

OpenVLA to RT-2-X is what Llama-3 is to GPT-4
OpenVLA to RT-2-X is what Llama-3 is to GPT-4
OpenVLA is an open-source generalist robotics manipulation model that is cost-efficient and customizable.


Foundation models have taken great strides in making robotics systems more robust to unpredictable situations and novel tasks. In the past year, we have seen many interesting projects that use LLMs and VLMs to help robotics systems reason about the scene and plan sequences of actions that can help them accomplish tasks they have not been trained for.
One interesting direction of research is vision-language-action (VLA) models that have been trained to directly map images and instructions to robotics actions. However, the state-of-the-art VLA models, such as RT-2 and RT-2-X, are not open and their data and training code are not available for others to build on. They have also not been designed to be customized for new tasks and robot morphologies.
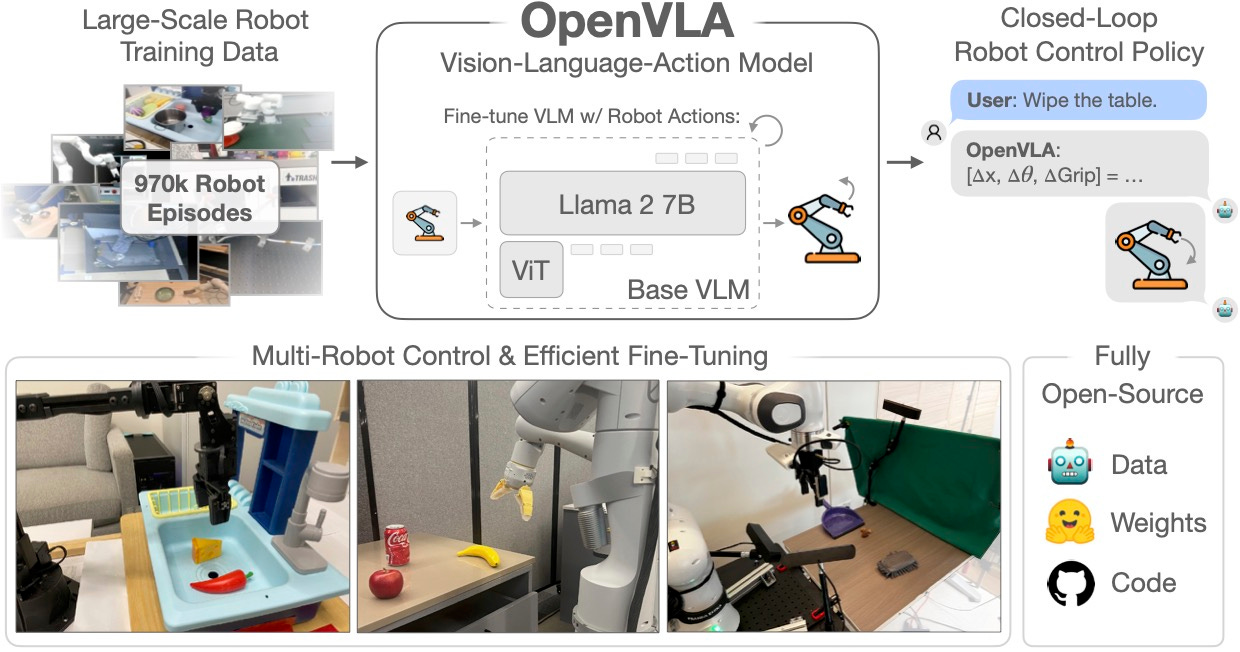
OpenVLA is an open-source generalist robotics model that addresses these shortcomings. OpenVLA has been created jointly by researchers Stanford University, UC Berkeley, Toyota Research Institute, Google Deepmind, and other labs.
The foundation for OpenVLA is Prismatic-7B, a VLM that uses a two-part visual encoder for extracting features from input images and a Llama-2 7B model to process language instructions.
The researchers configured the Prismatic model to output robotic action tokens instead of text. They then fine-tuned it on more than 900,000 robot manipulation trajectories from the Open-X Embodiment dataset, which spans a wide range of robot embodiments, tasks, and scenes.
According to the researchers, OpenVLA outperforms RT-2-X models on robotics tasks. It can also be fine-tuned for generalization in multi-task environments involving multiple objects and outperforms other fine-tuned policies.
The researchers designed OpenVLA to reduce the costs of fine-tuning and inference. The code supports low-rank adaptation (LoRA), a technique that only modifies a small subset of the model’s parameters when fine-tuning it for a downstream task. The result was an 8x reduction in the costs of fine-tuning in comparison to the full-parameter fine-tuning.
OpenVLA also supports quantization, a technique that reduces the byte-size of the model’s parameters while maintaining its accuracy. OpenVLA can be deployed on consumer-grade GPUs and deployed in environments where there is not a strong connection to the cloud.
The researchers have open-sourced all models, deployment and fine-tuning notebooks, and the OpenVLA codebase for training VLAs at scale. The library supports model fine-tuning on individual GPUs and training billion-parameter VLAs on multi-node GPU clusters. It is also compatible with modern optimization and parallelization techniques.
As we have seen with open LLMs such as the Llama series, making the model weights available to the research community will help accelerate innovation. OpenVLA will make it much easier for research labs and organizations to create their own robotics models and push the boundaries of what is possible with today’s technology.
Read more about OpenVLA on VentureBeat
Visit the OpenVLA project page
Read the paper on Arxiv
See the code on GitHub
Robots are a major trend. Musk said: "Their level of ubiquity will be ten times that of cars."