


A critical look at DeepMind's Genie 3
DeepMind's Genie 3 generates real-time, interactive worlds from a single prompt. But it remains to be seen if the approach is the final word on world models.


Google DeepMind has announced Genie 3, a general-purpose world model capable of generating interactive, navigable environments from a text prompt. The model renders these dynamic worlds in real time at 720p resolution and 24 frames per second, allowing a user to explore them with keyboard inputs.
This marks a significant development in world model research, moving from passive video generation to real-time, controllable simulation. However, whether there will be immediate valuable applications for such expensive models remains to be seen.
An emergent architecture for dynamic worlds
Genie 3’s real-time capability is powered by an auto-regressive architecture, the same mechanism used in large language models (LLMs). The model generates each new frame by considering the history of previously generated frames and the user's latest action. This process must happen multiple times per second to feel interactive.
Unlike techniques such as Neural Radiance Fields (NeRFs) or Gaussian Splatting, which require an explicit 3D representation to ensure consistency, Genie-3’s environmental consistency is an emergent property. The model builds its worlds frame by frame, allowing for more dynamic and rich environments that can be altered on the fly using text-based "promptable world events" to change weather or introduce new objects.
A generational leap in memory and interactivity
The model represents a substantial improvement over its predecessors. Genie 2, released in late 2024, had a memory that topped out at around 10 seconds. After this brief period, it would forget what parts of the world looked like once they were out of view. Genie 2 also wasn’t fast enough to run in realtime. GameNGen, another Google research project, provided an interactive environment rendered in real time. But it was low-resolution and was limited to the Doom game environment.
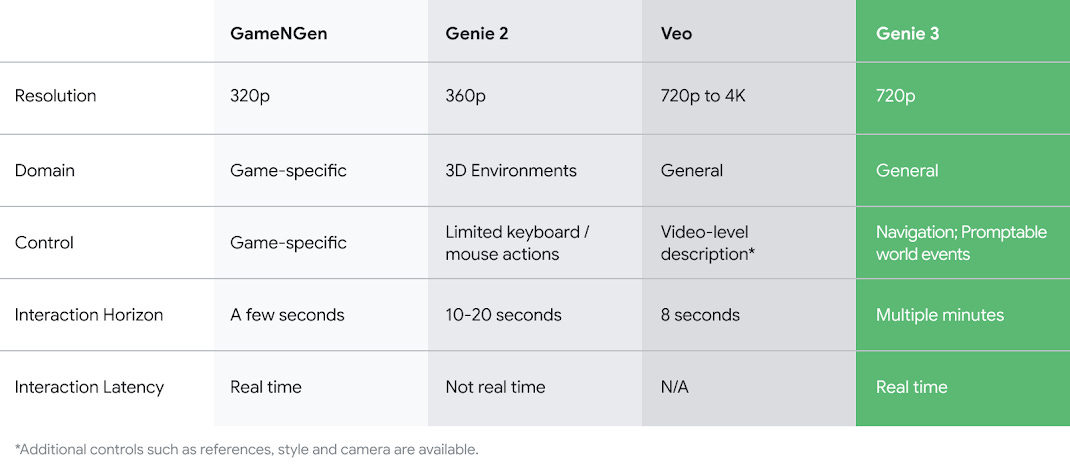
Genie 3 extends this "long horizon memory" to several minutes, maintaining visual consistency for a much longer duration of interaction. This extended memory, combined with its shift to real-time interactivity, addresses two of the most significant limitations of earlier foundation world models. Genie 3 also provides high-resolution renderings, making the scenes visually appealing.
The grand ambition: a simulator for embodied AI
DeepMind positions Genie 3 primarily as a research tool to advance embodied AI. In comments to journalists, as reported by AI Explained, lead author Jack Parker-Holder said the goal is to create a "Move 37 moment" for embodied agents (a reference to the novel, non-human strategy AlphaGo discovered in the game of Go).
The theory is that since we lack sufficient real-world data to train robots for every possible scenario, unlimited simulated worlds could allow agents to develop novel solutions. This implies that even DeepMind doesn’t know what the true use case of Genie 3 will be, but they know that there is something “magical” in there that, if probed properly, can turn out to be very useful and create immense value.
To test this, DeepMind has already used Genie 3 to generate worlds for its SIMA agent, which can pursue goals by sending navigation actions back to the model.
Present limitations
Despite its advances, Genie 3 has significant limitations. The interaction duration is capped at a few minutes, not hours, meaning worlds are not persistent (but the advances the team has made from Genie 2 to Genie 3 suggests that scaling the approach can continue to extend the model’s action and memory horizon).
The model also suffers from physics inaccuracies and occasional visual hallucinations, such as people appearing to walk backward. This raises a "reliability paradox" that Philip from AI Explained aptly presents: If these worlds suffer from physics inaccuracies, which they do, how could such agents ever be fully reliable? According to the lead researchers of the Genie 3 project, while the simulations are not reliable enough to guarantee an agent will perform correctly in the real world, they can be used to demonstrate unreliability if an agent fails within the simulation.
Further constraints include an agent action space limited to navigation, an inability to simulate real-world locations with geographic accuracy, and poor text rendering unless specified in the prompt. Complex interactions between multiple agents are also an ongoing research challenge. And for the moment, the model only takes in text prompts, so you can’t feed it with a base image (e.g., a photo from a real location or a screenshot from a game) and turn it into an interactive experience.
For now, Genie-3 is available only as a limited research preview for a small group of academics and creators. DeepMind has not provided a timeline for a general release, citing the need to understand and mitigate risks associated with its open-ended capabilities. The technology is a key part of the company's stated path toward AGI. Future developments will likely focus on extending interaction times, enabling more complex agent actions, and supporting dialogue with simulated characters.