
A reasoning model with native search capabilities
Interleaving search and reasoning makes a big difference and boosts LLM applications where they require access to external information.


As large reasoning models continue to make inroads in different applications, retrieval and search have failed to catch up with them. This makes it difficult to use LRMs in tasks that require access to search-based retrieval and up-to-date information.
SEARCH-R1, a new technique developed by researchers at the University of Illinois at Urbana-Champaign and the University of Massachusetts Amherst, solves this problems by training LLMs to interleave search and reasoning in their chain-of-thought (CoT) trace.
Two popular methods for integrating search engines with LLMs are Retrieval-Augmented Generation (RAG) and customizing the models for tool use either through prompt engineering or model fine-tuning. But both methods are limited.
RAG is especially limited in problems that require mutli-hop retrieval, which is essential for reasoning tasks. Prompting-based tool fails to generalize to different search interfaces and applications. And fine-tuning requires a large batch of carefully curated training examples.
SEARCH-R1 integrates the search into the reasoning process instead of relying on an isolated retrieval stage. Basically, a model trained on SEARCH-R1 works in the following fashion:
Reasons about the problem and determines the information it needs to retrieve from the web (enclosed in <think></think> tags)
Composes a search query (enclosed in <search></search> tags), which is then passed on to the search engine API
Integrates the search results into its context window (enclosed in <information></information> tags)
Continues to reason about the problem based on the new information and repeats the above process
Returns the answer (enclosed in <answer></answer> tags)
(see example below)

To simplify the process of training SEARCH-R1 models without the need for manually annotated data, the researchers used a pure reinforcement learning (RL) approach, where the model is left to explore the use of reasoning and search tools without guidance from human-generated data. The model is only rewarded or penalized based on its outcome, without direct evaluation of its reasoning/search process. It turns out that like DeepSeek-R1-Zero, an outcome-based reward is enough to create a decent model that can learn to use search tools without the need for human-annotated data.
“SEARCH-R1 can be viewed as an extension of DeepSeek-R1, which primarily focuses on parametric reasoning by introducing search-augmented RL training for enhanced retrieval-driven decision-making,” the researchers write in their paper..
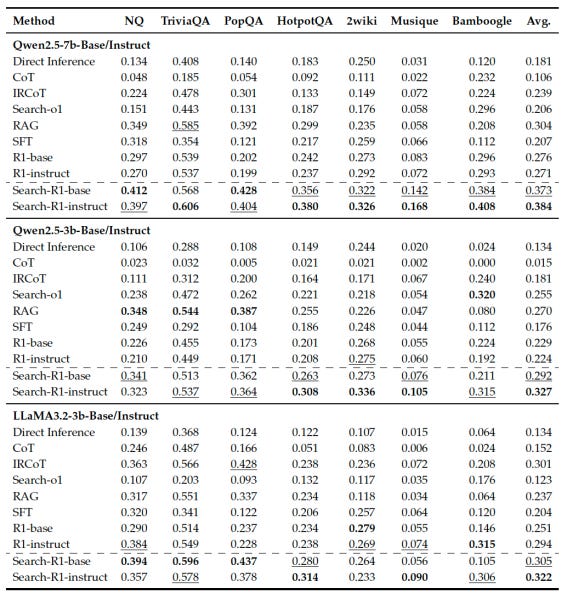
The researchers fine-tuned base and instruct versions of Qwen-2.5 and Llama-3.2 on SEARCH-R1 and evaluated them on reasoning tasks requiring single-turn and multi-hop search against direct inference with Chain-of-Thought (CoT) reasoning with R1, RAG, and supervised fine-tuning for tool use.
The results show that SEARCH-R1 consistently outperforms baseline methods by a fair margin. It also outperforms R1 without search retrieval, showing the practical implications of adding native search capabilities to reasoning models and hinting at the yet-untapped potential of pure RL approaches. The researchers have released the code for SEARCH-R1 on GitHub.
Really enjoyed this breakdown—SEARCH-R1 is a fascinating evolution in search-reasoning integration. The challenges it addresses around multi-hop retrieval and tool orchestration are very real, especially when the goal is high-precision decision-making over evolving knowledge.
We’ve been working on a system called BioMed Advisor (BmA) that tackles many of these same issues—but specifically for biomedical and public health workflows, where reasoning must often span multiple knowledge sources and models. BmA goes beyond single LLM pipelines by coordinating reasoning across multiple models and tools, using context-aware workflows like Chain-of-Thought and Tree-of-Thought with orchestration logic.
Would love to get feedback from others exploring this space. Happy to share more if it’s of interest. You can see more at biomedadvisor.com.