
A transformer model that learns at inference time
It's like LoRA, but it can also be adjusted at inference time to adjust the model's behavior to new tasks.


Transformer² (read Transformer-squared), a new model proposed by Sakana AI, can learn new tasks at inference time by modifying its weights at inference time.
This is an alternative to costly LLM fine-tuning, during which the model is exposed to new examples and its parameters are adjusted.
Transformer-squared uses a two-step approach to dynamically adjust its parameters. First, it analyzes the prompt to parse the task and the skills it requires. It then modifies the model’s weights to optimize it for that specific request.
To do this, it first uses singular-value decomposition (SVD) on the model weight to single out the key components that can be tweaked during inference. SVD is a linear algebra trick that breaks down a matrix into three other matrices that reveal its inner structure and geometry. When applied to LLM weights, SVD can find subsets that roughly represent different skills, such as math, language understanding, and coding. These components can then be tweaked to modify the model’s abilities in specific tasks.
The researchers also developed a novel technique called Singular Value Finetuning (SVF). During training, SVF learns a set of “z-vectors” from the SVD components of the model that represent individual skills. Z-vectors act like knobs that can amplify or dampen the model’s ability in specific tasks.
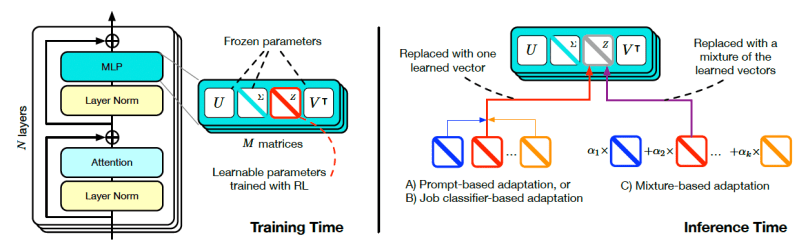
At inference time, Transformer-squared first examines the prompt to determine the skills required to tackle the problem. It then configures the z-vectors based on the required skills. It then combines the z-vectors with the model parameters and runs the prompt. This enables the model to provide a tailored response to each prompt. (If you know how LoRA works, think of z-vectors as a dynamic LoRA adapter that can be tuned at inference time.)
In their experiments, the researchers compared Transformer-squared to LoRA on various tasks, including math, coding, reasoning, and visual question-answering. Transformer-squared outperforms LoRA on all benchmarks with fewer parameters with the added benefit of being adjustable at inference time.
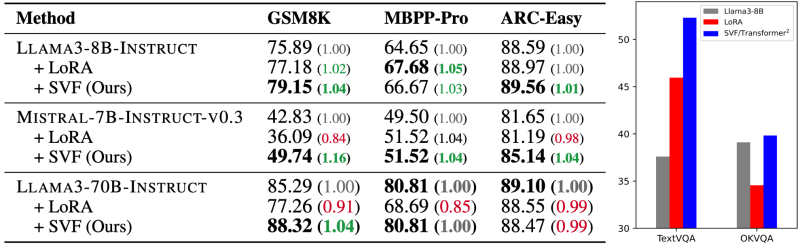
Interestingly, z-vectors can be transferred across models as long as they have compatible architectures.
“Self-adaptive systems like Transformer² bridge the gap between static AI and living intelligence, paving the way for efficient, personalized, and fully integrated AI tools that drive progress across industries and our daily lives,” the researchers write.
Sakana AI has released the code for training the components of Transformer-squared on GitHub.
A neural net modifying its own weights is likely not going to work well for very large and very finely-tuned networks. It will also be immensely expensive.
Identifying a subset of weights that can be made tunable is likely going to be very task-dependent and won't generalize.
I think it makes more sense for an AI agent to work hard at inference time, when the solution is not known, and save the final streamlined path to the solution, the way people record their own eventual polished strategies.
That way the AI agent builds a vast trove of recipes it discovers that can later be either fetched dynamically when dealing with similar problems, or baked in a future large training run.