
Automatic prompt engineering with PAS
PAS is an automated prompt engineering (APE) system that chooses the best prompting technique for each input to an LLM.


While LLMs can generate impressive results with simple prompts, you need prompt engineering techniques to get consistent and accurate responses. However, there are dozens of prompt engineering techniques and each is suitable for a specific range of tasks.
Prompt Augmentation System (PAS), a technique developed by Researchers at Peking University and Baichuan Inc, reduces the friction of using LLMs by automatically choosing the best prompting technique for user inputs.
PAS is a model that takes in a raw prompt and outputs the prompt with complementary instructions based on the type of task it aims to solve. PAS is a plug-and-play system that can be inserted into an LLM applications and works well with different types of LLMs.
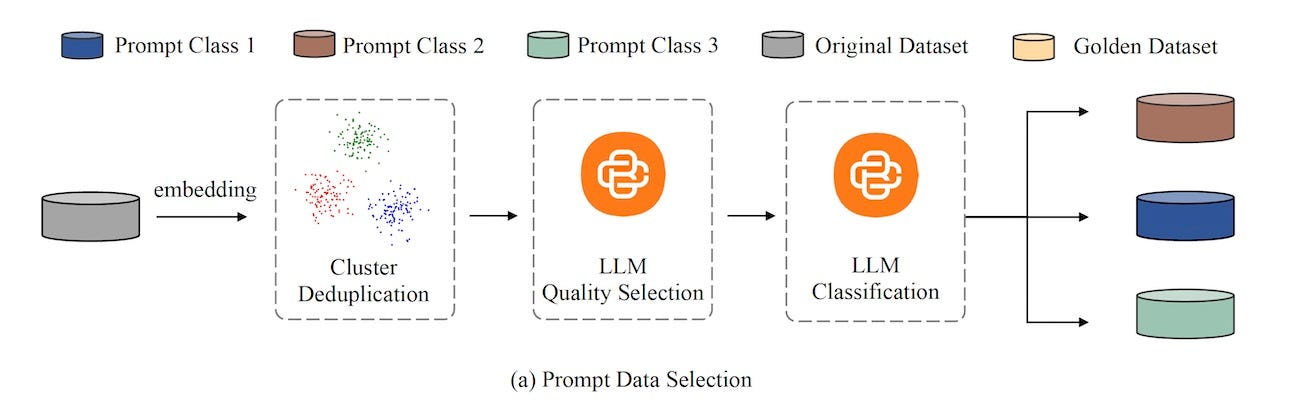
One of the challenges of PAS is creating the dataset to train the augmentation model. To address the problem, the researchers created an automated pipeline that automatically curates a dataset of diverse high-quality prompts for different types of tasks. It uses embedding models and clustering algorithms to find and filter duplicates, and then it uses frontier LLMs to classify the prompts based on their quality and type of task.
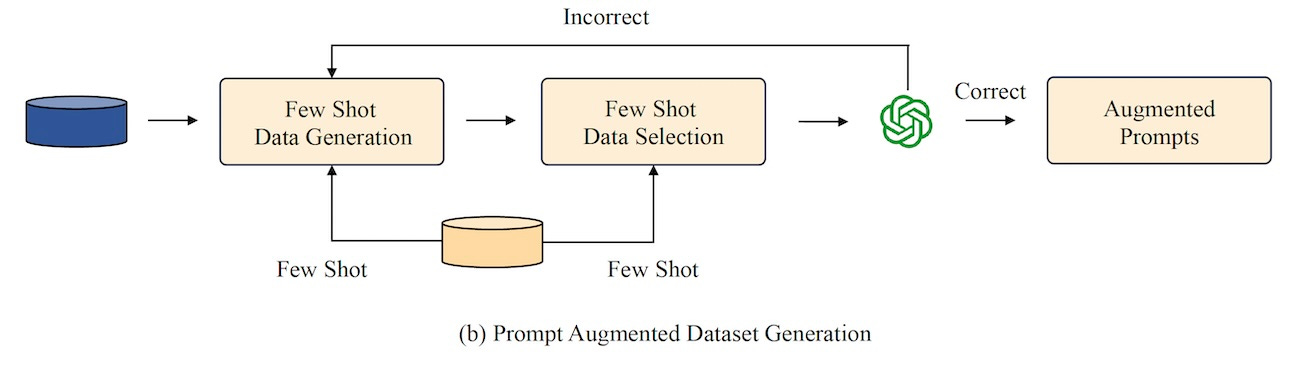
Next, it uses few-shot learning to add complementary instructions to the seed prompts selected in the previous step. The augmented prompt are then evaluated by an LLM, again with few-shot examples, and those that do not qualify are sent back for regeneration.
The researchers used this pipeline to automatically create a dataset with 9,000 high-quality prompt-augmentation examples. They then trained small LLMs (e.g., Llama-2-7B) on the dataset to create the PAS model.
This model was used to augment prompts given to larger models such as GPT-4 and Llama-3-70B. The responses were considerably superior to zero-shot prompting with the base models.
PAS is one of several automatic prompt-engineering (APE) techniques. But what sets it apart is:
It needs fewer training examples: It requires 9,000 training examples as opposed to other similar models that require up to 170,000 examples
It is model and task agnostic: The same model trained on the diverse dataset can be used for a wide range of tasks and can augment many different closed and open models.
It is plug-and-play: The PAS model does not need any knowledge of the downstream (or upstream) model in the pipeline and can directly be plugged into your application.
Read more about PAS on TechTalks
Read the paper on Arxiv
With the continuous accumulation of application and practical experience of Large Language Models (LLMs), the methodology of "how to write prompts" has gradually formed a new set of theories.
The PAS system, through automated prompt supplementation, has significantly improved the performance of LLMs, achieving an improvement of more than 6 percentage points compared to the previously state-of-the-art model, BPO.
Moreover, the achievement of PAS was accomplished with less than 65% of the fine-tuning data volume used by BPO, further demonstrating the advantage of PAS in data efficiency, and providing a strong guiding direction for the research and expansion of APE .