
Beyond chain-of-thought: A look at the Hierarchical Reasoning Model
With 27M parameters and 1,000 examples, HRM beats top LLMs on key reasoning benchmarks


Singapore-based AI startup Sapient Intelligence has developed a new AI architecture that can match the performance of large, complex models on reasoning tasks while being significantly smaller and more computationally efficient. The architecture, called the Hierarchical Reasoning Model (HRM), takes its cues from the way the human brain uses different systems for slow, deliberate planning and fast-paced, intuitive computations. With 27 million parameters and only 1,000 training examples, it can outperform multi-billion-parameter models on complex reasoning tasks.
The challenges of reasoning in large language models
Current large language models (LLMs) primarily solve reasoning problems through chain-of-thought (CoT), which forces the model to generate “thinking” tokens that verbalize the reasoning process, breaking a complex problem into a sequence of simpler, text-based steps. While effective to a degree, this approach has fundamental limits.
The reliance on explicit linguistic steps means that reasoning is tethered to token-level patterns, which often requires vast amounts of training data. It also forces the model to generate many intermediate tokens, leading to slow response times for complex tasks.
This method also fails to capture the latent reasoning that happens internally, without being articulated through language. Many of our own thought processes are not a running inner monologue but a series of non-verbal, abstract computations that cannot be expressed in text.
The paper’s authors argue that “CoT for reasoning is a crutch, not a satisfactory solution. It relies on brittle, human-defined decompositions where a single misstep or a misorder of the steps can derail the reasoning process entirely.”
This is why several studies show that CoT tokens can be misleading and do not necessarily reflect the LLM’s reasoning process.
The Hierarchical Reasoning Model
To build a more robust architecture, the researchers explored "latent reasoning," where the model performs computations within its internal hidden state. This hidden space is expressed in numerical values that do not directly translate into text tokens. This concept aligns with the view that language is a tool for communication, not the substrate of thought itself.
As the paper notes, “the brain sustains lengthy, coherent chains of reasoning with remarkable efficiency in a latent space, without constant translation back to language.”
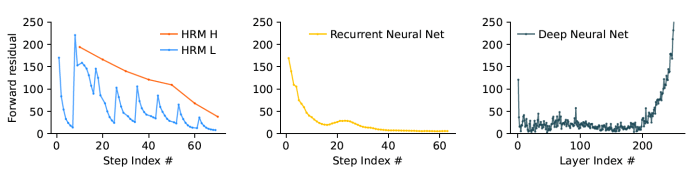
Achieving this kind of latent reasoning requires significant computational depth, something current models lack. Simply stacking more Transformer layers, the building blocks of most LLMs, leads to training instability due to the vanishing gradients problem, where the gradients of earlier layers start to diminish and eventually vanish as they cross through more and more layers.
Recurrent neural networks (RNNs), which are designed for sequential tasks, are another alternative, but they often get stuck in a suboptimal solution too early, a problem called premature convergence, where they get stuck in the first solution they find and avoid exploring other and potentially better alternatives.
Looking for a better way forward, the researchers turned to neuroscience for inspiration. “The human brain provides a compelling blueprint for achieving the effective computational depth that contemporary artificial models lack,” they write. “It organizes computation hierarchically across cortical regions operating at different timescales, enabling deep, multi-stage reasoning.”
The HRM architecture features two coupled recurrent modules that mirror this biological design: a high-level (H) module for slow, abstract planning and a low-level (L) module for fast, detailed work. These modules use many of the same components as the transformer model but have been arranged in a way that makes them more efficient for reasoning tasks.
These modules operate through a process the researchers call "hierarchical convergence." The fast L-module runs for several steps, exploring a part of the problem and settling on a local, intermediate solution. Once it stabilizes, the slow H-module takes this result, reflects on it, updates the overall strategy, and then resets the L-module with a new direction to explore. This nested computational loop prevents the model from converging too quickly and allows it to tackle problems requiring many steps.
This design gives the model a powerful internal reasoning engine that allows the HRM to perform a sequence of nested computations. In this reasoning scheme, the H-module “directs the overall problem-solving strategy” while the L-module “executes the intensive search or refinement required for each step.”
This architecture enables the model to reason through complex tasks without the need for computationally expensive CoT and deeply stacked layers. Since the reasoning is happening in the latent space of the model’s weights (as opposed to CoT tokens), HRM does not need human-written CoT examples.
The lack of CoT creates an interpretability challenge, making it difficult to investigate the model’s reasoning process (to be fair, CoT tokens do not necessarily reflect the reasoning process of LLMs). However, in their experiments, the researchers show that it is possible to trace the reasoning process of HRM models on various problems.

Putting HRM through its paces
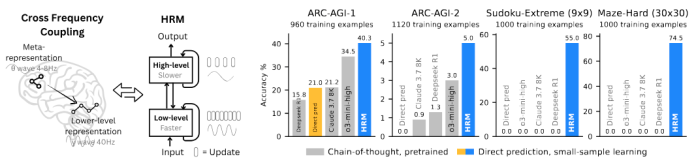
To test their model, the researchers used a suite of notoriously difficult benchmarks, including the Abstraction and Reasoning Corpus (ARC-AGI), an IQ-style test; Sudoku-Extreme, which requires deep logical search; and Maze-Hard, a complex pathfinding challenge. The results showed that HRM excels at tasks requiring extensive search and backtracking. Using only about 1,000 training examples and without any pre-training or CoT, HRM learned to solve problems that are intractable for even advanced LLMs.
For example, on complex Sudoku puzzles and 30x30 mazes, HRM achieved near-perfect accuracy, while leading CoT-based models failed completely with 0% accuracy. On the ARC-AGI benchmark, an HRM model with just 27 million parameters achieved 40.3% accuracy, substantially outperforming larger, pre-trained models like Claude 3, which scored 21.2%.
By moving beyond the limitations of text-based reasoning, HRM offers a promising new direction for artificial intelligence. "The prevailing AI approach continues to favor non-hierarchical models," the authors conclude. "Our results challenge this established paradigm and suggest that the Hierarchical Reasoning Model represents a viable alternative to the currently dominant chain-of-thought reasoning methods, advancing toward a foundational framework capable of Turing-complete universal computation."
Great summary. Thanks