
Byte-level transformers solve the problems of tokenized LLMs
Meta's BLT model learns directly from raw bytes instead of tokenizing them, opening ways for new applications.


Scientists at Meta and the University of Washington have introduced a new transformer architecture that removes tokenization, one of the most important parts of the model. Called Byte Latent Transformer (BLT), the new architecture learns directly from bytes instead of tokens and solves one of the longstanding problems of LLMs that operate at byte level.
Tokenization makes LLMs more efficient in using compute resources but also introduces challenges. For example, tokenized LLMs slow down when and lose accuracy faced with misspelled words or words that were not included in their token vocabulary. Tokenized models also struggle with character-level tasks, such as manipulating sequences. Changing the vocabulary requires retraining the model or even the architecture itself.
In contrast, byte-level models solve many of the abovementioned problems by directly learning and manipulating bytes. But they are prohibitively costly to train and scale at long sequences.
BLT solves the challenges of byte-level models and matches the performance of tokenized LLMs. Instead of tokens, BLT uses a special algorithm that dynamically groups bytes into patches at inference time based on entropy measures. BLT does this dynamic patching through three transformer blocks: two lightweight byte-level encoder/decoder models and a large “latent global transformer.”
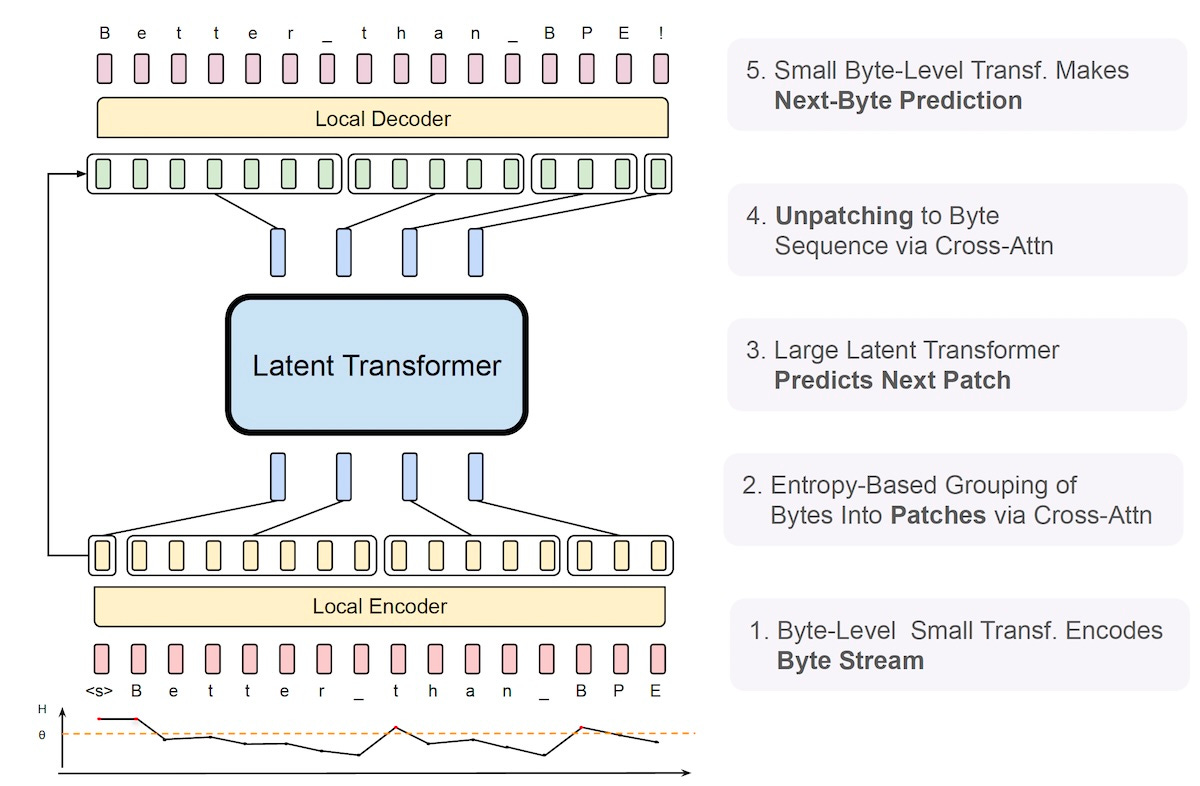
The encoder takes in input bytes and creates the patch representations. The latent global transformer takes in the patch representations generated by the encoder and predicts the next patch in the sequence. At the other end, the local decoder takes the batch representations processed by the global transformer and decodes them into raw bytes.
The global transformer consumes the largest share of compute resources during training and inference. Therefore, the patching mechanism determines the amount of compute used for different portions of the input and output.
BLT makes it possible to allocate compute resources based on the complexity of the data instead of the vocabulary size.
The researchers conducted experiments with BLT and classic transformers on models of different scales, running from 400 million to 8 billion parameters.
According to the experiments of the researchers BLT matches the performance of Llama 3 with less than half the FLOPS.
“To the best of our knowledge, BLT is the first byte-level Transformer architecture to achieve matching scaling trends with BPE-based models at compute optimal regimes,” the researchers write.
BLT models are also more robust than tokenized models when handling noisy inputs. They are better at character-level tasks, translating low-resource languages, and working with patterns that don’t appear often in the training corpus.
This new architecture has joined the ranks of several contenders that are competing with the classic transformer model. While BLT still has a long way to go, it can certainly find a niche for specialized applications.