
ByteDance's new fine-tuning technique boost LLMs for reasoning tasks
Reinforced Fine-Tuning is a new technique that improves the performance of LLMs for Chain-of-Thought reasoning tasks.


One of the important areas of interest for large language models (LLM) is planning and reasoning tasks. Experiments show that providing models with reasoning examples, also called “Chain-of-Thought reasoning” (CoT), improves their accuracy on such tasks. These capabilities can be crucial in applications that require careful planning and coordination among several agents.
Fine-tuning the models on CoT examples makes them even better at reasoning. However, classic CoT fine-tuning methods have limited effectiveness. A new study by researchers at ByteDance introduces Reinforced Fine-Tuning (ReFT), a new training algorithm that brings considerable improvements to CoT fine-tuning. ReFT combines classic supervised fine-tuning (SFT) with reinforcement learning (RL) to generalize CoT capabilities.
The main advantage of ReFT is that it is a complement to existing CoT fine-tuning techniques and can be applied without the need to generate or annotate new examples.
SFT and ReFT
The traditional method to train LLMs for reasoning tasks is supervised fine-tuning. The engineering team must gather a set of CoT examples to fine-tune the LLM. The examples can be created manually or with the help of a strong LLM like GPT-4.
In this method, there is one chain-of-thought per training example, which narrows the model’s reasoning path and results in weak generalization. In reality, there may be several valid CoT paths to the solution.
Reinforced Fine-Tuning (ReFT), the new technique proposed by ByteDance, solves this problem by letting the model discover new reasoning paths. According to the paper, “ReFT optimizes a non-differentiable objective by exploring multiple CoT annotations in the search for the correct answer, rather than relying on a single CoT annotation.”
ReFT starts with one or two epochs of SFT on annotated CoT examples. This “warm-up stage” conditions the model to generate correct responses to logical problems. Next, ReFT further refines the model through an online reinforcement learning algorithm.
The RL model adjusts its policy by repeatedly generating CoT responses, evaluating their correctness, and updating its parameters. This enables the ReFT to discover several correct reasoning paths or CoT annotations and learn generalized solutions. Since the training examples include ground-truth answers, the model can generate and evaluate its reasoning steps without the need for extensive manual labels.
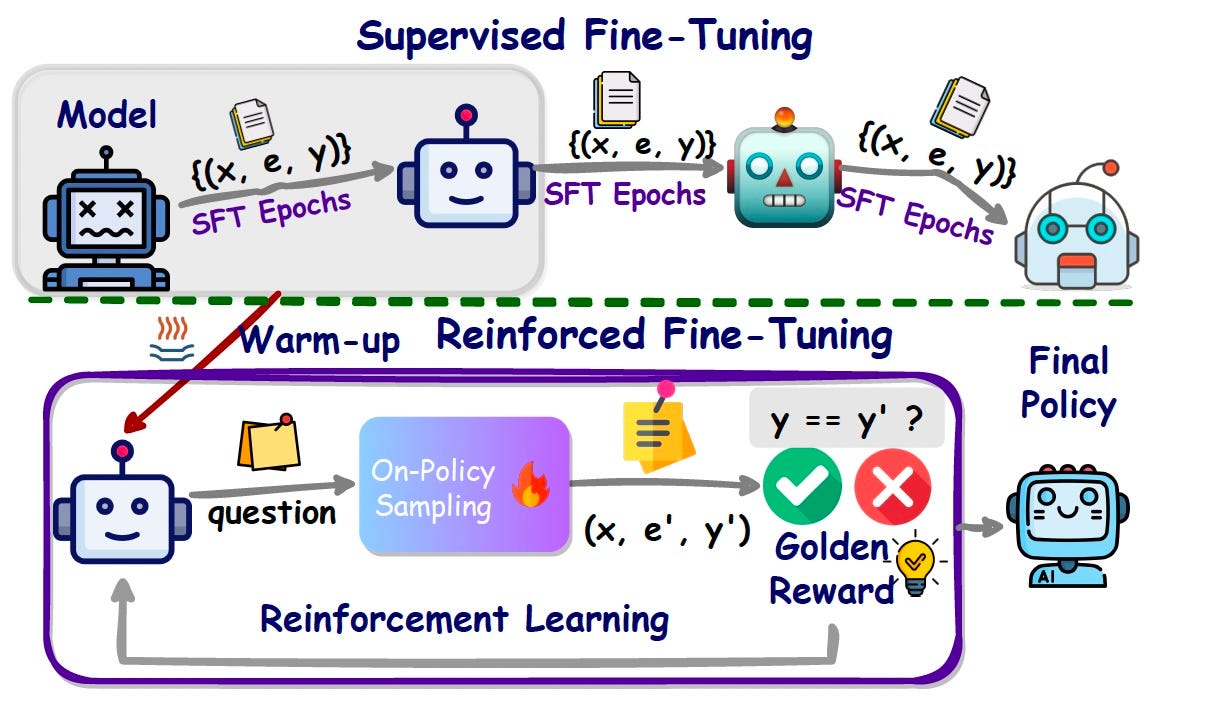
Per the paper: “During the warm-up stage, ReFT acquires a certain level of accuracy by supervised learning. In the RL stage, ReFT further enhances its ability by reinforcement learning through sampling various CoT reasoning paths. In this way, ReFT gets much richer supervision signals than SFT.”
One important advantage of ReFT is that it uses the same training questions as SFT, without relying on extra or augmented training questions. Therefore, if an engineering team already has an SFT dataset for CoT fine-tuning, they can use ReFT without additional data-gathering efforts.
ReFT in action
The researchers used GPT-3.5 to generate chain-of-thought annotations for three math reasoning benchmarks in their experiments. They used two different modes of CoT, one that uses natural language reasoning and another that generates executable Python code for its reasoning steps.
The researchers trained two open-source models, Galactica-6.7B and CodeLlama-7B, on the baseline SFT and ReFT methods. The SFT baseline only trained the models on the generated CoT examples. ReFT “warmed up” the model with the examples and used reinforcement learning to generate and explore other CoT solutions.
The researchers’ experiments show that models trained on ReFT outperform SFT consistently on reasoning benchmarks, sometimes by 9%. Using CoT with Python code produces more accurate results because the model’s reasoning steps can be automatically evaluated with a code interpreter.
Interestingly, CodeLlama-7b fine-tuned for CoT with ReFT and augmented with reward model reranking slightly outperforms GPT-3.5 Turbo on the famous GSM8K benchmark.
However, ReFT is not a perfect solution. The paper’s findings show that the method is prone to “reward hacking,” where it seeks shortcuts to the final result without going through the right reasoning steps. This happens because in the RL phase, the model is rewarded for the final answer, not the reasoning steps. Therefore, the model might generate a series of unrelated reasoning steps but be rewarded because it produces the correct token at the end of the sequence.
This problem is especially present in the natural language CoT mode because the reasoning steps can’t be verified. The programming mode can be verified with a code executor, which is also why the code-based CoT training produces more accurate results.
ReFT also requires more training epochs than SFT to reach convergence. “This is primarily due to the fact that ReFT optimizes a non-differentiable objective and requires exploration of the generation space to attain correct answers,” the researchers write.
The bigger picture
There is a large body of research dedicated to studying the behavior of LLMs and comparing them to humans. But since we humans tend to anthropomorphize AI systems, we also like to think about them in terms of human intelligence.