
Chain-of-Experts is the new upgrade for MoE
A simple change to the architecture makes mixtu-of-expert LLMs much more efficient

Mixture of experts (MoE) has become a popular architecture to make large language models (LLMs) more resource-efficient. It is used in DeepSeek-R1, GPT-4, and many other large LLMs.
Chain-of-Experts (CoE), a new framework proposed by researchers from different universities, addresses the limitations of MoEs while also making them more efficient.
What are the limits of MoEs?
The classic architecture for LLMs (aka “dense models”) activates all parameters for each input. In contrast, MoEs divide the model’s parameters into several learned “experts,” each of which specializes in some tasks. During inference, a router component selects a subset of experts to activate for each input, making it computationally more efficient than dense models. For example, DeepSeek-V3 has 671 billion parameters divided into 257 experts. At inference, nine experts are routed, totally to 37 billion active parameters at any given time.
But MoEs have two limitations: 1) Experts are not connected, reducing the model’s performance on tasks that require coordination. And 2) MoE models are highly sparse, which means that they have high memory requirements even if a small subset of parameters are used at any given time.
Chain of Experts
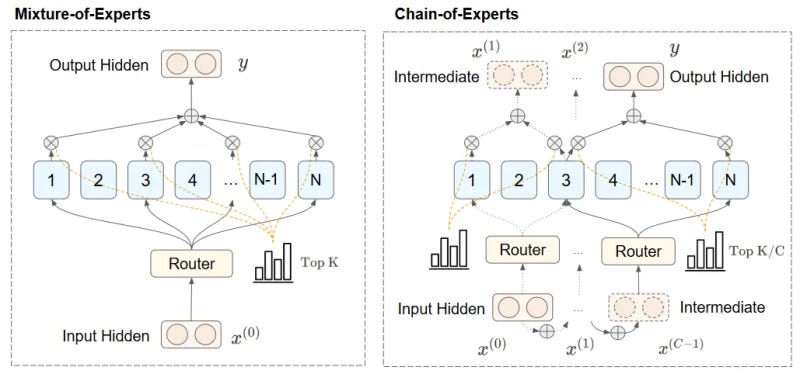
While MoEs activate experts in parallel, CoE routes them in a sequence. For example, when the model receives an input, instead of activating eight experts in parallel, routes to four experts and uses their output to choose another set of four experts that are best suited for the intermediary results. This iterative process can be repeated multiple times. This mechanism enables experts to communicate, build interdependencies, and gradually build on each other’s work.
The researchers tested CoE against dense LLMs and MoEs on different tasks. Their experiments show that CoE outperforms the other two with equal compute and memory budgets. For example, on mathematical tasks, a CoE with 64 total experts, four routed experts, and two iterations—codenamed CoE-2(4/64)—outperfoms an MoE with eight active experts from 64 total experts—MoE(8/64). The same CoE also provides 823 more expert combinations in comparison to the MoE(8/64), enabling the model to learn more complex tasks without increasing the size of the model.

The novel mechanism of CoE can be exploited in other ways. For example, a CoE with two of 48 routed experts and two iterations (CoE-2(4/48)) achieves performance similar to MoE(8/64) while using fewer total experts, reducing memory requirements by 17.6%.
Alternatively, you can make the model leaner. For example, a CoE-2(8/64) with four layers of neural networks matches the performance of an MoE(8/64) with eight layers but 42% lower memory.
The researchers describe this gain as a “free lunch” acceleration: “By restructuring how information flows through the model, we achieve better results with similar computational overhead compared to previous MoE methods.”