
Data poisoning and adversarial attacks

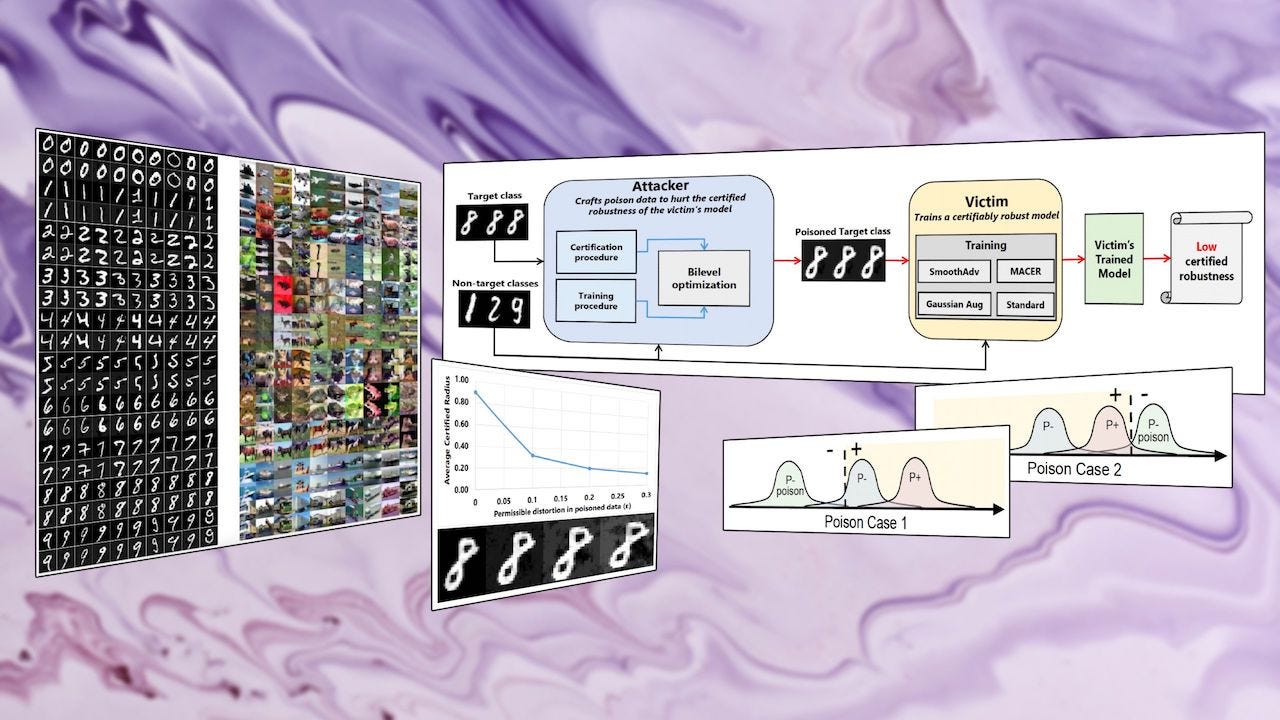
In recent years, artificial intelligence researchers have developed various ways to protect machine learning systems against adversarial attacks. Among the most popular techniques is “randomized smoothing,” a series of training methods that establish a certified radius within which adversarial perturbations don’t affect machine learning models.
But a new paper by AI researchers at Tulane University, Lawrence Livermore National Laboratory, and IBM Research shows that machine learning systems can fail against adversarial examples even if they have been trained with randomized smoothing techniques. The paper has been accepted at this year’s Conference on Computer Vision and Pattern Recognition (CVPR) and sheds light on previously overlooked aspects of adversarial machine learning.
Read the coverage of the paper and interview with the lead author on TechTalks.
For more on adversarial attacks: