


DeepMind's GenRM combines LLM verifiers with LLM-as-a-Judge
It outperforms current LLM-based verification methods


Researchers at DeepMind and other institutions have introduced GenRM, a new LLM verification technique that outperforms other popular methods such as discriminative verifiers, self-consistency, and LLM-as-a-Judge.
Current LLM-based verifiers are typically trained as discriminative reward models (RMs) to assign numerical scores to candidate solutions and classify them as correct or incorrect. However, these RMs do not fully use the strengths of LLMs in generating and processing responses.
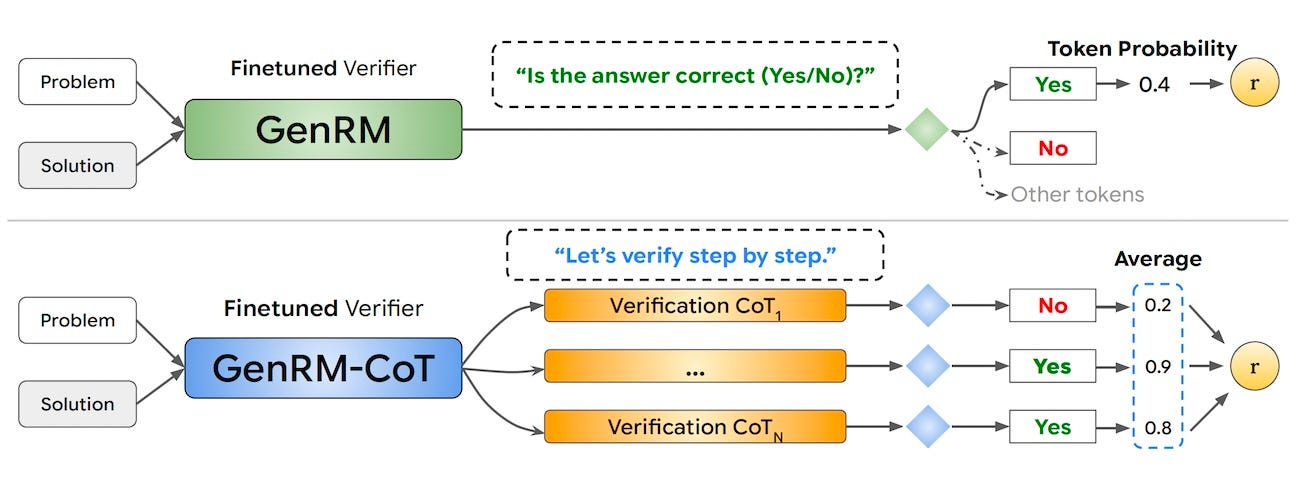
GenRM trains verifiers using next-token prediction to leverage the text generation capabilities of LLMs. For example, to produce a numerical score for a response, the verifier uses a prompt such as “Is the answer correct?”, and represents the score as the probability of a single text token (e.g., “Yes” or “No”).
Unlike classic verifiers, GenRM can benefit from advanced prompting techniques such as chain-of-thought (CoT). GenRM can be viewed as an LLM-as-a-Judge that has been trained on domain-specific data.
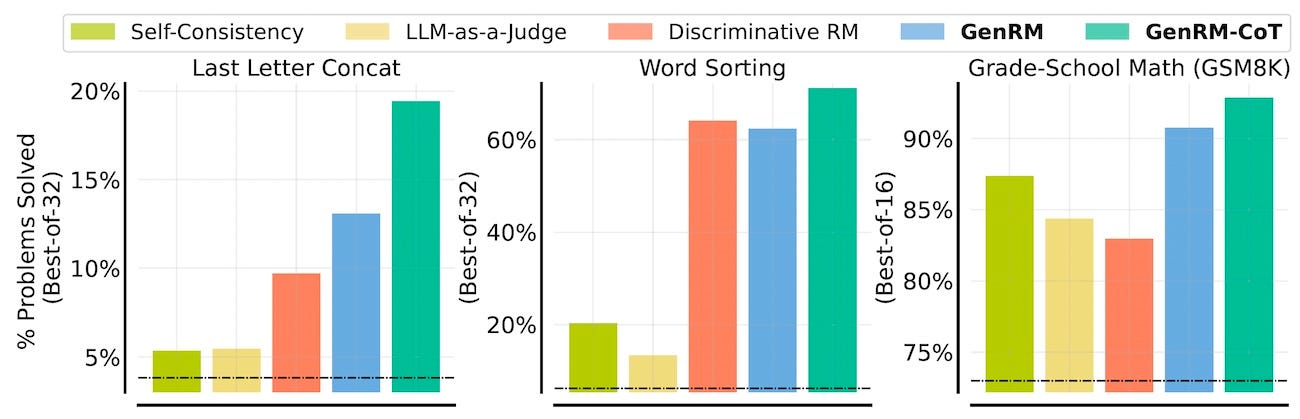
When tested across various reasoning task tasks, GenRM consistently outperformed the other methods. On the GSM8K math reasoning benchmark, a Gemma-9B model trained for GenRM even surpassed the performance of GPT-4 and Gemini 1.5 Pro.
The experiments also showed that GenRM scales favorably with increasing dataset size and model capacity. Furthermore, GenRM with CoT continues to improve when allowed to sample more responses. This gives more flexibility to LLM application developers to balance accuracy, training, and compute costs.
Read more about GenRM along with comments from the lead author in VentureBeat
Read the paper on arXiv