
DeepMind's new RL is a better teammate for humans

From Go to StarCraft to Dota, artificial intelligence researchers are creating reinforcement learning systems that can defeat human experts at complicated games. But the bigger challenge of AI is creating RL systems that can team up with humans instead of competing with them.
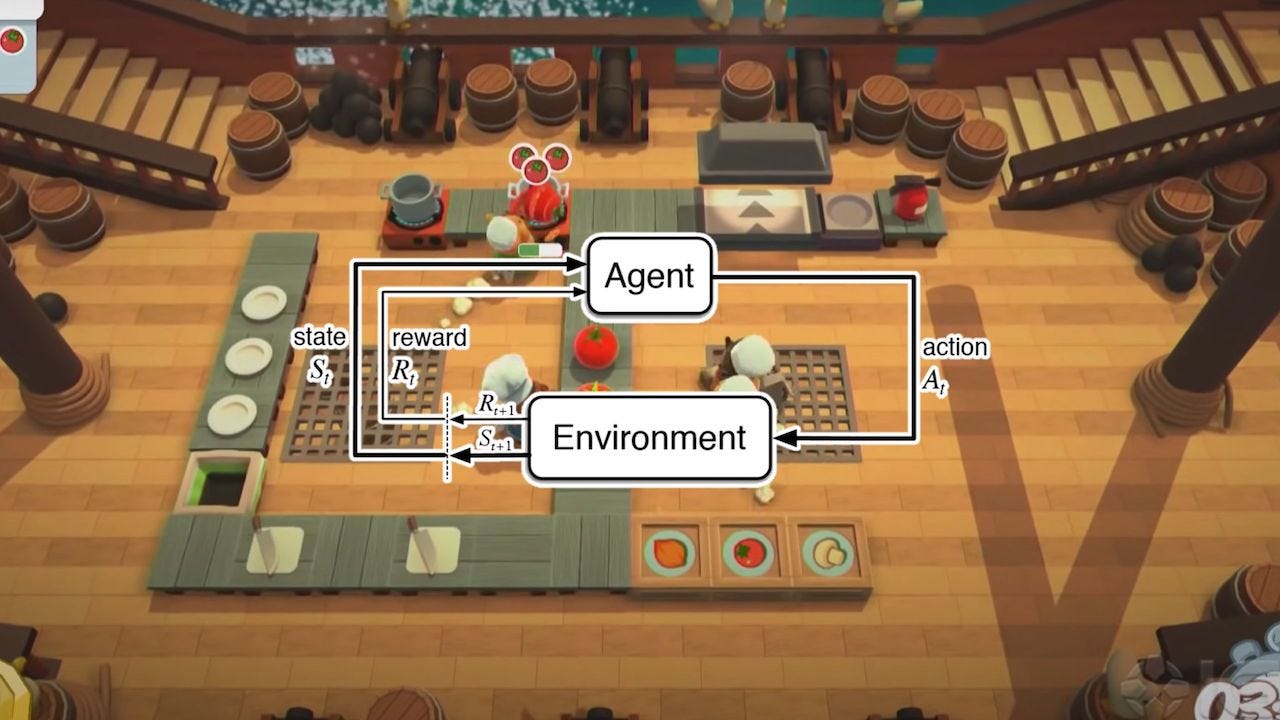
In a new paper, AI researchers at DeepMind present a new technique to improve the capacity of reinforcement learning agents to cooperate with humans at different skill levels. Accepted at the annual NeurIPS conference, the technique is called Fictitious Co-Play (FCP) and it does not require human-generated data to train the RL agents.
When tested with the puzzle-solving game Overcooked, FCP created RL agents that provided better results and caused less confusion when teamed up with humans. The findings can provide important directions for future research in human-AI systems.
Read the full article on TechTalks.
For more on reinforcement learning research: