
Don't evaluate compressed LLMs based on accuracy
Compressed LLMs maintain their accuracy metrics in comparison to the baseline models. But their behavior changes dramatically, according to other metrics.


LLM compression methods such as quantization and pruning have become very popular as the costs of running large language models remain high. However, when it comes to evaluating the abilities of compressed LLMs, metrics are not very well defined.
The common way to measure the quality of model compression is to compare the performance of the compressed and base LLMs on popular benchmarks such as MMLU and Hellaswag. However, a new study by Microsoft shows that while compressed models match the accuracy metric of the base model, their behavior changes dramatically.
The main driver of this change is what the researchers call “flips,” where the model changes its answers, some from correct to incorrect and vice versa. This is why the overall accuracy measure remains similar. But if the goal of a compressed LLM is to reproduce the behavior of the base model, then flips can have a substantial effect on their performance, especially on generative tasks that require free-form responses.
There are many nuances to flips, such as why they happen and why they are not evenly distributed across all answers in question-answering problems. But the main takeaway is that accuracy alone is not the right metric to evaluate the outcome of model compression.
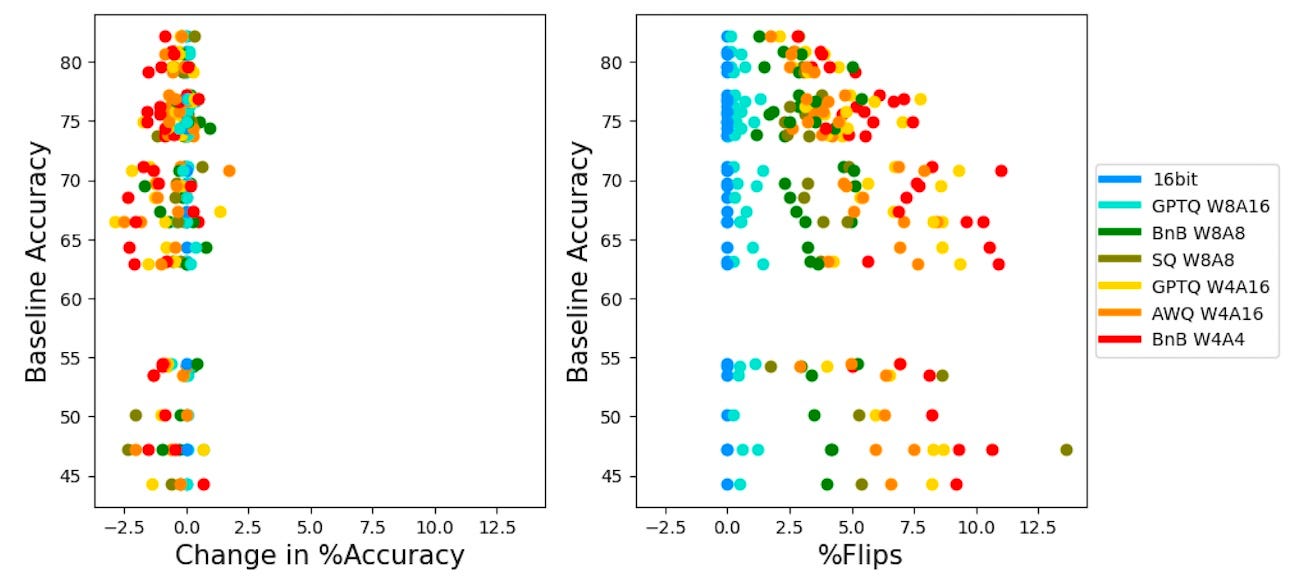
Instead, the researchers suggest that in addition to accuracy, developers should use “distance” metrics that measure the similarity between the base and compressed model. For example, KL divergence correlates with flip rates and is a good measure of how the answer distributions differ between the two models.
These findings are important, as quantization and other compression methods are often used as optimization techniques to reduce the costs of LLMs in downstream applications. In such conditions, especially in generative tasks, you want to make sure that the optimized model reflects the behavior of the original LLM.
Read more about the details of the paper and its findings on TechTalks.
Read the paper “Accuracy is Not All You Need.”