
Evaluating the limits of chain-of-thought on planning
A new study shows that chain-of-thought (CoT) prompts only improve large language models (LLM) on very narrow planning tasks and don't generalize broadly.


Originally published here
Large language models (LLM) are often touted as general problem solvers that can be configured to do new tasks on the fly. And in some cases, this is true. One popular example is “chain-of-thought” (CoT), a popular prompting technique that improves the performance of LLMs on planning and reasoning tasks.
But an open question is what exactly the model learns through CoT and how far it can be trusted. A new study by Arizona State University sheds light on the limitations of chain-of-thought prompts in planning tasks. The findings show that the improvements caused by CoT prompts do not stem from the LLM learning algorithmic procedures.
Chain-of-thought prompting remains an important tool for LLM applications. But knowing its limitations will help you avoid its pitfalls.
Chain-of-thought prompting
CoT is part of a wider range of techniques that leverage the “in-context learning” (ICL) abilities of LLMs. Basically, ICL involves adding a list of problem-solution pairs to the prompt to teach the model a new task or focus it on a specific skill.
In chain-of-thought, each example is annotated with intermediate reasoning steps that show how to reach the solution from the problem. After receiving the CoT examples, the LLM is expected to output a similar series of reasoning steps prior to the new answer.
CoT was first proposed in a paper by Google Research, which suggested that the technique "allows reasoning abilities to emerge naturally" in LLMs. A later paper presented “zero-shot reasoning,” a prompting technique that activates reasoning powers in LLMs by appending the phrase “let’s think step by step” to the prompt.

It is easy to anthropomorphize the behavior of LLMs, and the impressive results of CoT are very convincing. Several studies and experiments show that CoT significantly enhances LLM performance in complex reasoning tasks.
Ideally, a properly constructed prompt should teach the LLM to generalize a basic algorithmic procedure to a large class of problems. This would help convert a modest amount of human teaching effort into a significant capability boost. However, LLMs are very different from human intelligence, and it is not clear what the model learns from CoT prompts.
The study by Arizona State University does a systematic investigation into the generalizability of CoT prompting. It tries to answer the question of how similar the CoT examples must be to the target problem. More technically, it evaluates the “out-of-domain generalization” of chain-of-thought prompting and its practical implications.
“We are interested in the tradeoff between possible performance gains from chain of thought prompt engineering and the amount of human labor necessary to generate examples with correct reasoning traces,” the researchers write.
The challenge of evaluating CoT
Studies on chain-of-thought reasoning typically use test benchmarks such as GSM8K and CommonSense QA, datasets of question-answering problems that require logical and commonsense reasoning skills. However, there are two main problems with these benchmarks.
First, they don’t have a systematic method to scale instances, which is essential for evaluating whether LLMs can extend the CoT logic to larger instances of the same type. And second, they are well-represented on the web, which increases the possibility that they were part of the LLM’s training data. This can make it difficult to understand whether the model is learning to reason through CoT or is just finding ways to focus its in-memory knowledge.
To evaluate the limits of CoT, the researchers focus on Blocksworld, a commonsense problem domain in which a set of blocks needs to be arranged from an initial arrangement to a goal configuration. The advantage of Blocksworld is that it has well-defined ground truths that can be checked algorithmically as opposed to requiring manual reviews. Blocksworld problems can also be formulated in measurable levels of difficulty and at scale, making it possible to evaluate the effectiveness of CoT prompts at different levels of specificity.

The general assumption of CoT is that the broader and more general the provided knowledge is, the more problems it can be applied to, and the less human prompt-crafting it requires. On the other hand, the more specific the prompt, the higher it should perform on the narrow set of tasks.
“While previous work has touted the effectiveness of the technique, we are interested in examining this tradeoff across two axes: prompt granularity and reasoning step count,” the researchers write.
CoT on Blocksworld
The researchers tested the performance of GPT-4 and Claude 3 Opus on different classes of Blocksworld problems and CoT prompts of different granularity and specificity.
The chain-of-thought prompts range from a very general zero-shot instruction to a prompt that is specific to a subset of Blocksworld stacking problems. The most general prompt could be applied to any problem, while the least is specific to an easy version of the stacking problem.
Their findings include two key observations: First, as the size of the goal stack increases, the model’s accuracy drops drastically regardless of the specificity of the chain of thought prompt. So, if you provide the model with examples of stacking four blocks in alphabetic order and give it a problem with 20 blocks, it will most likely fail. This is in contrast to humans, who are very good at inferring logical rules from a few examples.
Second, as the generality of the prompt increases, the model’s performance decreases on even small stacks, and it sometimes underperforms zero-shot prompts. In contrast, humans are efficient at transferring learned skills across domains.
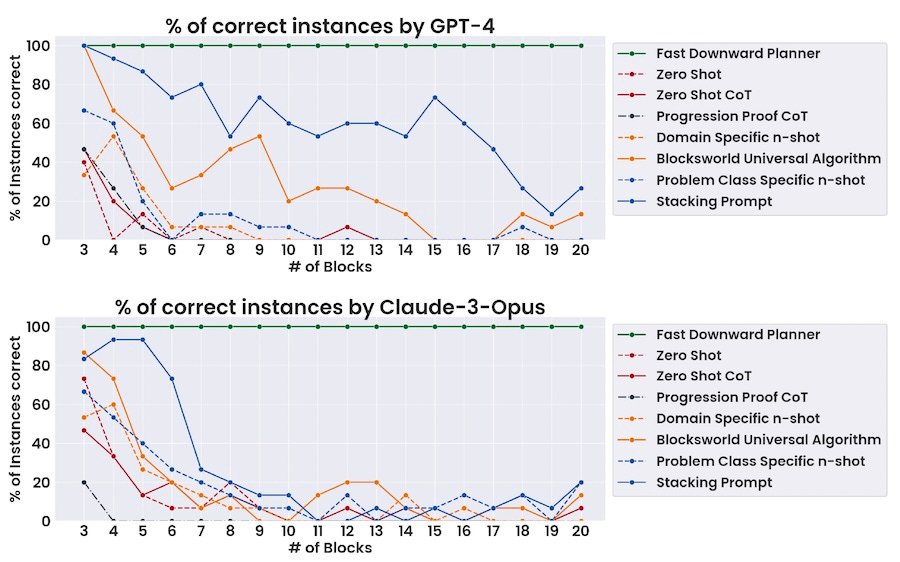
The findings show that CoT prompts may only work consistently within a problem class if the problem class is very narrow and the given examples are specific to that class.
“Our results reconfirm that LLMs are generally incapable of solving simple planning problems, and that chain of thought approaches only improve performance when the hand-annotated examples and the query are sufficiently similar,” the researchers.
Implications for practical applications of CoT
“If chain of thought is meant to replicate human thinking or learning, it should generalize beyond the most direct pattern matches and allow for more robust reasoning across extremely similar problems,” the researchers write.
At the very least, this means you should be wary of results from CoT prompting. LLMs may show human-like performance in complicated tasks, but you should acknowledge that their inner workings are very different from the human brain, which can cause incompatibilities and unpredictable failures. There is no proof that the generation of reasoning steps in the output affects the model’s inner reasoning process. A recent study shows that you can replace the chain-of-thought process with meaningless tokens and still get good results.
This also has important implications for the practical application of CoT in applied fields. Unless there is a rich set of annotated examples that are similar enough to the target problem, CoT might not provide reliable results. Otherwise, you have to assess whether the manual effort required to create CoT examples is worth the results.
Nonetheless, this does not mean that CoT is not useful. LLMs have a vast knowledge of the world and can be very useful in some reasoning tasks, especially if there is a mechanism to verify the results. For example, DrEureka, a system developed by University of Pennsylvania and Nvidia, uses GPT-4 to reason about robotics tasks and create multiple candidates for reward functions. The reward functions are used to train reinforcement learning policies. The model is then instructed to reflect on the results and improve the function. The results are superior to hand-crafted results thanks to the basic reasoning abilities of the models and the ability to run many instances in parallel.
The study by Arizona State University also provides a good criterion to evaluate future models and CoT techniques: “If chain of thought approach es lead to more than just simple pattern matching, and can in fact teach language models to perform generalizable, compositional reasoning, then we should expect that to be reflected in robust and maintainable improvements on a simple commonsense benchmark set like Blocksworld.”