
Google releases EmbeddingGemma, slowly builds a powerful ecosystem of AI models
This compact embedding model is a key piece in a larger strategy of small language models, favoring a fleet of efficient specialists models over one large LLM.


While the AI community is waiting for the release of Gemini 3, Google is pursuing a complementary strategy to its family of flagship large language models: building a fleet of small, specialized models designed for efficiency. Following the recent release of the Gemma 3 270M small language model, the new EmbeddingGemma arrives as its purpose-built counterpart.
EmbeddingGemma is an encoder-only model that can generate embeddings for search, classification, similarity measurement, and more. This makes it a crucial component for enabling powerful, private AI that runs entirely on your device.
Under the hood: the architecture of EmbeddingGemma
EmbeddingGemma delivers state-of-the-art text understanding for its size. It is the highest-ranking open multilingual text embedding model with under 500 million parameters on the Massive Text Embedding Benchmark (MTEB), the gold standard for text embedding evaluation.
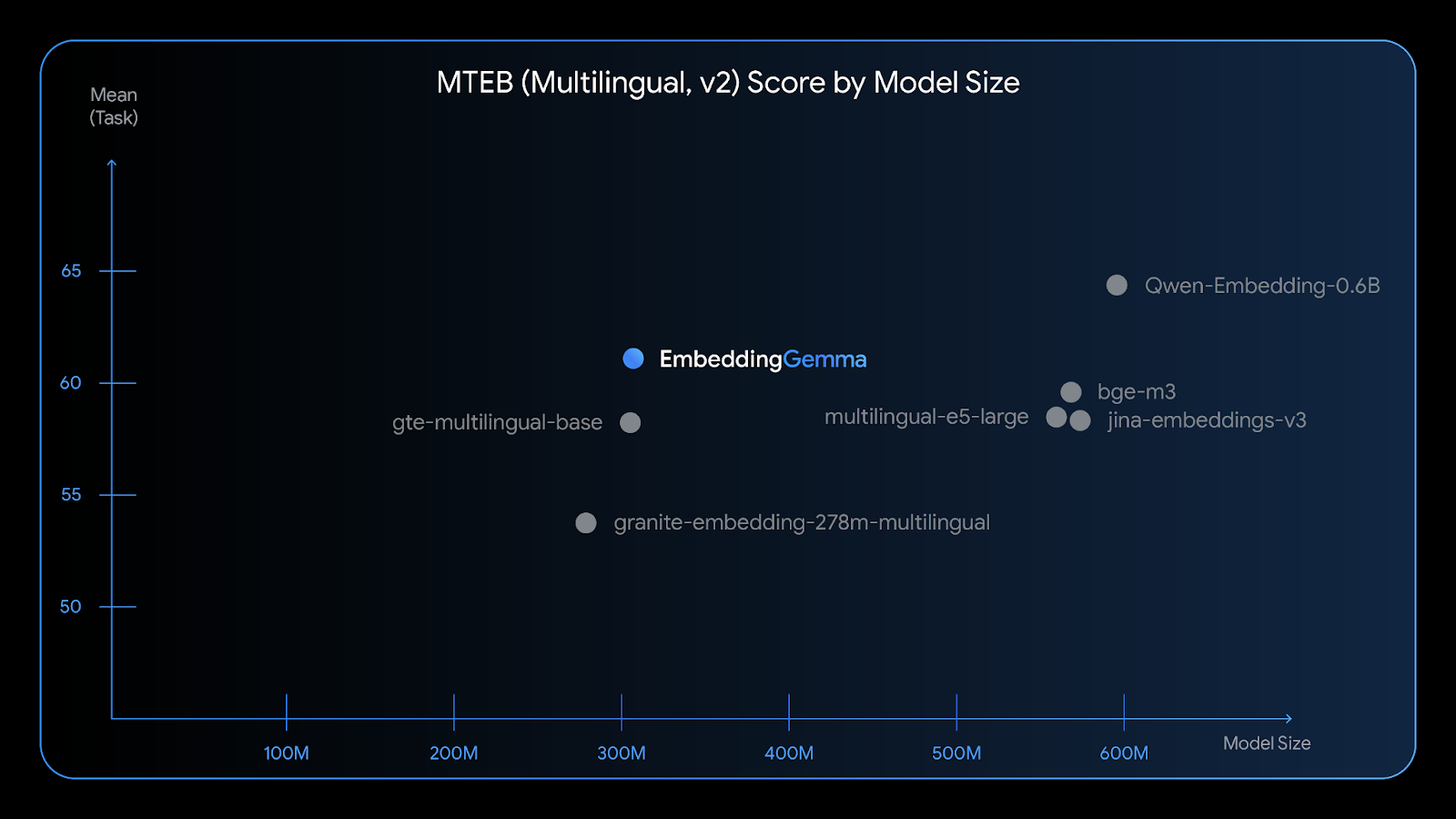
The model has 308 million parameters and was trained on over 100 languages, giving it broad applicability. Its design is focused on efficiency; with quantization, the model can run on less than 200MB of RAM, making it suitable for resource-constrained hardware like mobile phones.
The model's performance comes from an architecture tailored specifically for creating embeddings. It uses a Gemma 3 transformer backbone but modifies it with bi-directional attention. This allows the model to consider the full context of a text sequence, turning it into an encoder, which can outperform standard decoder-based LLMs on embedding tasks. This encoder-only design is a deliberate choice, reflecting the same philosophy of task-specific specialization seen in other compact Gemma models.
Two key techniques make EmbeddingGemma highly efficient. The first is Quantization-Aware Training (QAT). Instead of training the model at full precision and then compressing it, QAT incorporates the low-precision format into the training process itself. This method significantly reduces the final model's size and memory requirements while preserving high accuracy.
The second technique is Matryoshka Representation Learning (MRL). This approach, which takes its name after Russian nesting dolls, trains the model to place the most important information in the initial dimensions of its output vectors. This allows developers to use the full 768-dimension embedding for maximum quality or truncate it to smaller sizes like 256 or 128 for faster processing and lower storage costs, all from the same model. The MRL scheme makes sure to keep the most important information if you truncate the dimensions of the output.
Real-world applications of EmbeddingGemma
One of the important applications for EmbeddingGemma is powering on-device retrieval-augmented generation (RAG), where it works in tandem with its generative siblings. In this system, EmbeddingGemma generates high-quality embeddings from queries and documents, which can then be used by a vector store to find the most relevant information from a user's local documents. Once found, this context is passed to a compact "generator," such as a Gemma 3 model, to produce a grounded response.
This two-model approach allows each component to do what it does best, creating a powerful and efficient system on-device. This enables private, personalized search across a user's emails, notes, and files without any data leaving the device. One of the interesting examples shown by the Google team uses EmbeddingGemma to populate an on-device vector store from the web pages a user has visited. The user can then query that store for a richer search into their browsing history.
Other applications of EmbeddingGemma include classification. For example, you can use it to perform sentiment analysis on emails and social media posts on your browser.
How to access EmbeddingGemma
EmbeddingGemma is available through popular hubs like Hugging Face and Kaggle. For developers, EmbeddingGemma integrates directly into major AI frameworks including Sentence Transformers, LangChain, and LlamaIndex, simplifying its use in existing workflows. The model is also supported by a range of popular local inference tools like Ollama, LMStudio, and llama.cpp, with MLX offering optimized performance on Apple Silicon. For web-based AI, it can run directly in the browser via Transformers.js.
EmbeddingGemma is also designed for customization. Developers can fine-tune the model for a specific domain or task to achieve even stronger performance. In one example, the Hugging Face team fine-tuned the base model on the Medical Instruction and Retrieval Dataset (MIRIAD). The resulting model achieved a significant performance improvement on the task of retrieving passages from scientific medical papers. It ultimately outperformed general-purpose embedding models that were twice its size, demonstrating the potential for creating highly specialized and efficient tools for specific industries.
EmbeddingGemma fits within the vision of a "fleet of specialists," where complex tasks are handled not by one monolithic model, but by a collection of smaller, purpose-built components.
In this paradigm, EmbeddingGemma is a foundational Lego block—the "retrieval" piece. It is designed to work alongside other models like the Gemma 3 270M model. This composable approach offers lower costs, higher speed, and better accuracy for specific tasks. It also provides greater control and privacy by enabling key operations to run on edge devices without sending sensitive data to a third-party cloud service.
There is ongoing discussion on whether scaling large language models with more data and parameters has reached the point of diminishing returns. But for what we can see, small models are just getting started.