
Google's Titans architecture is a game-changer for long-term memory in LLMs
The secret sauce is neural long-term memory modules


Titans, a new Transformer architecture developed by researchers at Google enables LLMs to extend their memory without exploding the costs of memory and compute.
The classic Transformer architecture uses the self-attention mechanism to compute the relations between all token pairs. While self-attention is very precise, its computing and memory costs increase quadratically as the input sequence grows longer.
Linear alternatives to attention have lower memory costs but are not as accurate. The ideal architecture, according to the Google researchers, should fashioned after the human brain and have different memory components to coordinate existing knowledge, memorize new facts, and learn abstractions directly from the context. This is what the Titans architecture solves
The key component of the Titans architecture is the “neural long-term memory,” which complements the attention layers. During training, the neural memory module learns a function for memorizing new facts during inference. This memorization mechanism can dynamically adapt as the data it encounters changes, enabling it to generalize to different data patterns.
The neural memory module uses “surprise” to decide which bits of information need to be memorize. It does this by comparing new tokens to the previous data it has seen and storing the data that is very different (i.e., surprising) from its existing knowledge. This enables the module to use its memory efficiently and store data that add useful information to what the model already knows.
To handle very long sequences of data, the neural memory module has an adaptive forgetting mechanism that allows it to remove information that is no longer needed, which helps manage the memory's limited capacity.

Titan model has three key components: The “core” module, which acts as the short-term memory and uses the classic attention mechanism to attend to the current segment of the input tokens that the model is processing; a “long-term memory” module, which uses the neural memory architecture to store information beyond the current context; and a “persistent memory” module, the learnable parameters that remain fixed after training and store time-independent knowledge. (The researchers propose different methods to connect the three components.)
The main advantage of this architecture is enabling the attention and memory modules to complement each other.
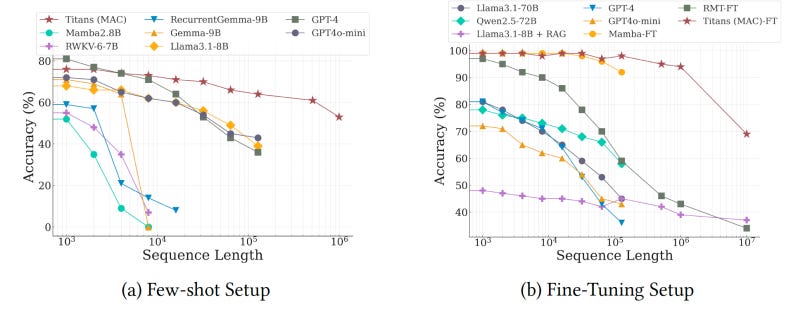
Experiments on models ranging from 170 million to 760 million parameters show that Titans outperforms classic Transformers, Mamba, and hybrid models such as Samba.
The performance difference is especially pronounced in tasks on long sequences, such as “needle in a haystack” and BABILong, a test where the model must reason across facts distributed in very long documents. In fact, Titan outperformed models with orders of magnitude more parameters in these tasks, including GPT-4 and GPT-4o-mini, and a Llama-3 model enhanced with retrieval-augmented generation (RAG).
Titans is also scalable up to 2 million tokens while maintaining the memory costs at a modest level. The models still need to be tested at larger sizes, but Titans still has a lot of untapped potential. It will be interesting to see how it pans out in the next year as Transformer alternatives continue to evolve.