
Grok 4 Fast redraws the AI pareto frontier of cost and intelligence
xAI's latest model achieves top-tier performance on par with competitors like Gemini 2.5 Pro while slashing costs by 98%, signaling a new era for developers.


xAI has released Grok 4 Fast, a new model that significantly lowers the cost of accessing high-end artificial intelligence. Grok 4 Fast is (as the name suggests) faster and cheaper than other models while also requiring less tokens to solve complex problems.
Independent reviews show that the model achieves an intelligence level comparable to Google’s Gemini 2.5 Pro but at a price approximately 25 times lower.
With the prices of state-of-the-art models constantly dropping and frontier AI becoming commoditized, developers have a growing number of options to build powerful AI applications.
The efficiency equation
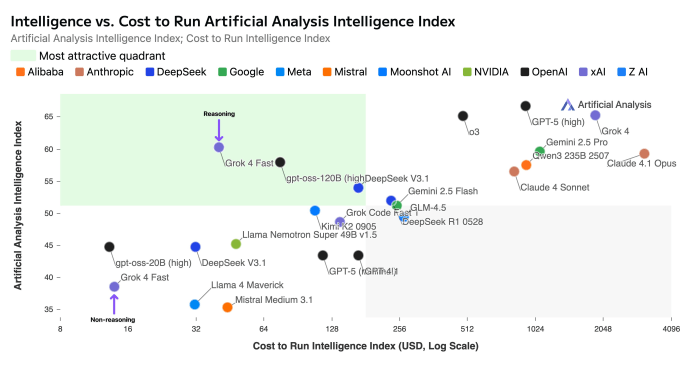
The model's main advantage is its cost-efficient intelligence. This is a result of both lower token pricing and superior token efficiency. According to xAI, Grok 4 Fast uses 40% fewer "thinking tokens" on average to solve problems than its predecessor, Grok 4. With reasoning tasks generating up to tens of thousands of tokens, such efficiency can result in significant cost reduction for applications.
This efficiency, combined with new pricing, leads to a 98% reduction in the cost to achieve the same performance as the previous model. The model also features a large 2 million token context window, allowing it to process and analyze extensive documents and complex prompts. In comparison, Gemini 2.5 currently supports 1 million tokens, GPT-5 has a 400,000 token context window, and Claude Opus 4.1 supports 128,000 tokens. Longer context windows are especially important for applications that require multiple documents and large code bases.
The model’s efficiency was confirmed in external benchmarks. To complete the Artificial Analysis Intelligence Index, Grok 4 Fast used 61 million tokens. This is significantly fewer than the 93 million tokens used by Gemini 2.5 Pro and nearly half the 120 million tokens required by the full Grok 4 model for the same set of tasks.
What we know about the architecture of Grok 4 Fast
Unfortunately, there is no information on the architecture of Grok 4 (hopefully, xAI will open source it when it releases Grok 6, as it has done with Grok 2). But according to the xAI blog, Grok 4 Fast introduces a “a unified architecture where reasoning (long chain-of-thought) and non-reasoning (quick responses) are handled by the same model weights, steered via system prompts.” According to xAI, this design reduces latency and token costs, making the model suitable for real-time applications that need to switch between different levels of computational depth.
This is similar to the approach taken by models such as Anthropic Claude 3.7 and later, which use special tokens to activate the reasoning mechanism of the model. Another approach is the one taken by OpenAI GPT-5, which uses a “router” to channel prompts to different versions of the model depending on whether they need chain-of-thought (CoT) reasoning or not.
There are a few other interesting aspects about the training that was mentioned in the blog. First, the token efficiency was performed through an optimized reinforcement learning (RL) process. RL has become an important part of training large reasoning models. One approach, as used in DeepSeek-R1-Zero, is to put no constraints on the model during the RL phase and only evaluate its response based on the final answer. However, this can result in the model overthinking and exploring illogical paths. A more advanced approach (which might also be used in Grok 4 Fast) is to gradually add additional reward signals, such as the length of the response, to incentivize the model to not only get the correct answer but also optimize its reasoning chain.
Another interesting aspect of the model is that Grok 4 Fast was “trained end-to-end with tool-use reinforcement learning,” which improves its ability to decide when to use external tools like web browsing or code execution. This is particularly important for a few reasons. First, tool use is a cornerstone of agentic applications. Second, tool-use through RL enables the model to learn new ways to employ tools without the need for human labeled data.
Performance and applications of Grok 4 Fast

On reasoning benchmarks, Grok 4 Fast scored 60 on the Artificial Analysis Intelligence Index, placing it in the same performance tier as Gemini 2.5 Pro and Claude 4.1 Opus. It performed particularly well on coding evaluations, securing the top spot on the LiveCodeBench leaderboard and outperforming the larger Grok 4. In public evaluations on the LMArena platform, the model ranked first in the Search Arena and eighth in the Text Arena, performing on par with the full Grok 4. Pre-release API benchmarks recorded an output speed of 344 tokens per second, about 2.5 times faster than OpenAI’s GPT-5 API.
One of the model’s primary applications is agentic search. It can browse the web and X, processing real-time data including text, images, and videos to synthesize answers. In particular, the integration with X data can give it a huge advantage when it comes to research tasks that require real-time information from what people are posting on the social network. (Social media integration is also tricky as the xAI team will have to figure out signals that indicate which posts contain relevant information and which are stale or misleading. For example, there is a recent trend on X where users with high follower counts are posting old AI research papers and presenting them as scientific breakthroughs.)
The commoditization of advanced AI
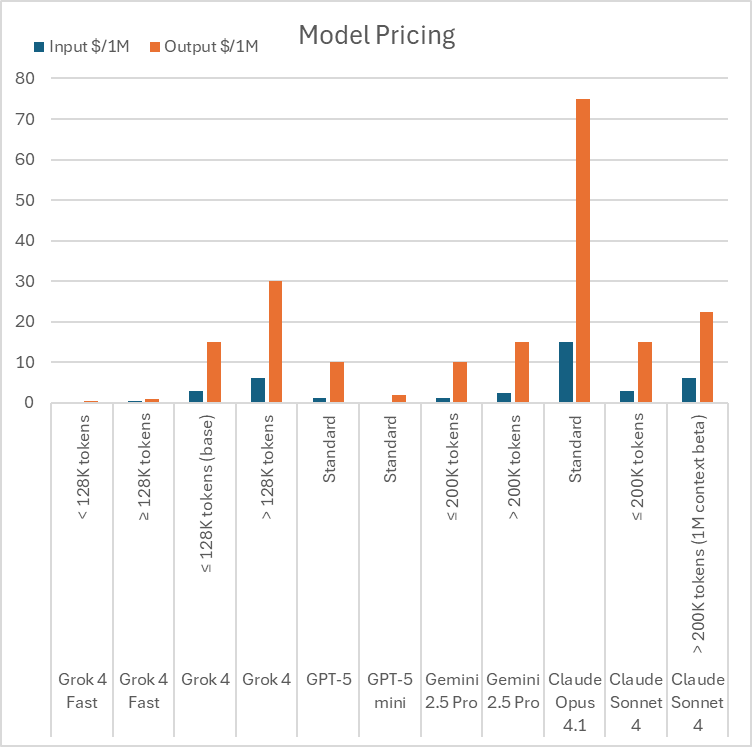
Grok 4 Fast is now available to all users on grok.com and its mobile apps, including those on the free tier. For developers, the model is accessible through the xAI API as two endpoints: grok-4-fast-reasoning and grok-4-fast-non-reasoning. Pricing is set at $0.20 per 1 million input tokens and $0.50 per 1 million output tokens for contexts under 128,000 tokens. For contexts that surpass 128,000 tokens, the price is $0.50 and $1.00 per million input/output tokens. This is considerably more affordable than GPT-5, Gemini 2.5 Pro, and the Claude 4 series, giving developers a powerful tool to build applications at a fraction of the previous price.
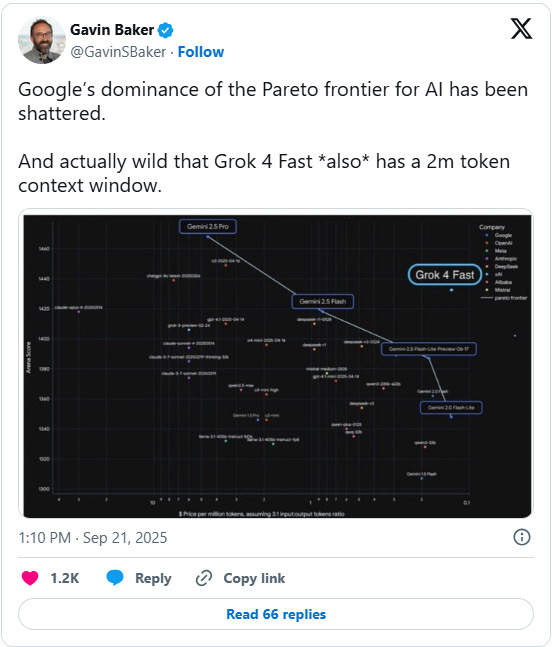
There is still a heated debate about whether LLMs have hit a wall and whether scaling data, compute, and model size will continue to yield breakthroughs. But what is for sure is that the unit price of intelligence is dropping, and that itself can result in massive gains and unlock many new opportunities and applications.