
How effective are inference-time scaling techniques?
Simply throwing more compute at a problem doesn't guarantee better or more efficient results.


Evaluating inference-time scaling techniques on LLM performance is not straightforward. And a new study from Microsoft Research shows that the effectiveness of these techniques varies significantly across models, tasks, and problem complexities, and simply throwing more compute at a problem doesn't guarantee better or more efficient results.
The researchers tested nine leading foundation models, including “conventional” models (e.g., GPT-4o, Claude 3.5 Sonnet, Gemini 2.0 Pro) and reasoning models (e.g., o1, o3-mini, Claude 3.7 Sonnet, Gemini 2.0 Flash Thinking, DeepSeek-R1) on three inference-time scaling approaches: Standard chain-of-thought (CoT), parallel scaling (generate multiple answers and use an aggregator to choose the final result), and sequential scaling (generate an answer and iterate on it based on feedback from a critic).

The researchers evaluated the techniques and LLMs across the dual axes of accuracy and computational cost.
Findings
1- Reasoning models generally outperform conventional LLMs on reasoning tasks, but gains can diminish on more complex problems (e.g., math vs science problems).
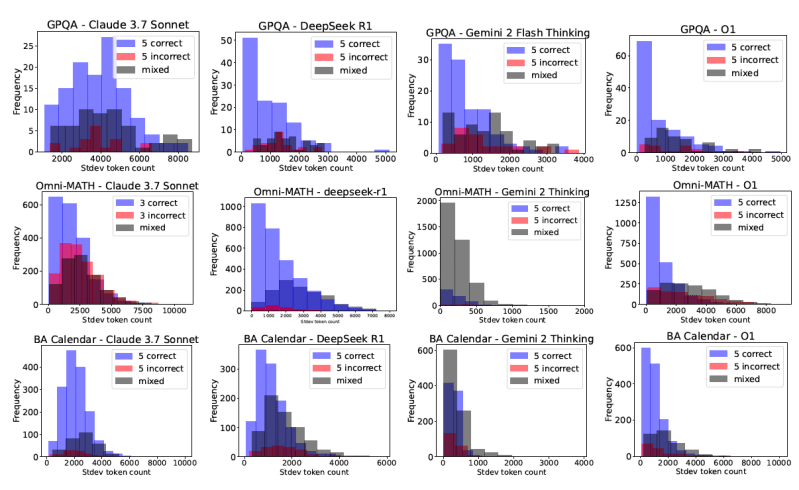
2- Token consumption varies significantly across different models and tasks. For example, DeepSeek-R1 used 5x more tokens than Claude 3.7 Sonnet on AIME 2025.
3- Longer CoT chains do not necessarily translate to better reasoning. “Surprisingly, we also observe that longer generations relative to the same model can sometimes be an indicator of models struggling, rather than improved reflection,” the researchers write.
4- Token usage variance by the same model on the same problem can fluctuate significantly. This makes it hard to predict inference costs of reasoning models.

5- Reliable verification mechanism can significantly boost the performance of all models on all tasks.
6- When allowed to generate more responses, conventional models like GPT-4o can often reach the performance of reasoning models, especially on less complex tasks.

What does it mean for developers? First, the profile of models and scaling techniques can help you have a better evaluation of the kind of costs you can incur at inference time. Preferably, you’ll want to choose models that have more stable response lengths for a given type of task (i.e., models that peak blue to the left in the following diagram).
The findings can also help you better understand model behavior. For example, after around 11,000 tokens, the following model’s responses are less likely to be correct, meaning that you can stop inference to avoid spending compute resources on a model that is struggling with a wrong reasoning chain.

Finally, the performance boost from perfect verifiers can help guide future research on building robust and broadly applicable verification mechanisms. Strong verifiers can also become a central part of agentic systems.