
How Gemma 3 270M can usher in a new paradigm in LLM applications
Google's Gemma 3 270M is a blueprint for a more sustainable AI ecosystem, where massive models help train fleets of specialized, cost-effective agents.


While the race for building ever larger language models continues, Google is championing a different philosophy with its new Gemma 3 270M model. Instead of a single, massive generalist, this small language model (SLM) is engineered as a highly efficient foundation, designed for developers to fine-tune for specific tasks. It provides a pathway towards building AI that strikes balance between efficiency and capability.
Architecture built for efficiency
The Gemma 3 270M is the smallest member of a diverse model family. Its larger siblings (4B, 12B, and 27B) are multimodal and feature a 128K context window, designed for higher-end hardware. In contrast, both the 270M and the 1B models are text-only with a 32K context window, targeting low-resource environments. The motivation for this new, even smaller model came directly from user adoption data. The 1B model saw an order of magnitude more downloads than the 27B model, signaling a strong developer demand for highly efficient, accessible models.
The model's architecture is tailored for this specialized role. Of its 270 million parameters, 100 million form the transformer blocks responsible for processing, while a substantial 170 million are dedicated to embeddings. A notable aspect of this architecture is that the embedding table (at roughly 168 million parameters) is larger than the model's processing layers (100 million parameters). As Ravin Kumar, a researcher on the Gemma team, explained in an interview with the Vanishing Gradients podcast, this was a deliberate choice: "We wanted to give people the flexibility to fine-tune this model to where they needed it to go, and a larger embedding table allowed for that."
This design, combined with a 256K tokenizer shared across the Gemma family, makes the model highly adaptable to new languages and specialized vocabularies. Google chose a dense architecture (instead of mixture-of-experts) for its simplicity and tunability, providing a flexible starting point for developers.
To ensure the model runs efficiently on resource-constrained devices, Google provides checkpoints that are Quantization-Aware Trained (QAT). (Quantization is a compression technique that reduces the number of bits per model parameter to save memory.) QAT technique simulates low-precision operations during the training phase, which minimizes the performance degradation that typically occurs when a model's parameters are compressed.
This allows Gemma 3 270M to run at INT4 precision (4 bits per parameter) with minimal loss in accuracy. The result is extreme energy efficiency; internal tests on a Pixel 9 Pro showed the INT4-quantized model used just 0.75% of the battery to conduct 25 conversations.
The full-precision version of Gemma 3 270M requires around 0.5 GB of memory (16 bit per parameter) while the INT4-quantized version cuts memory to around 125 MB. (Note: In reality, loading the model also requires additional memory for things such as KV cache.)
Performance where it counts
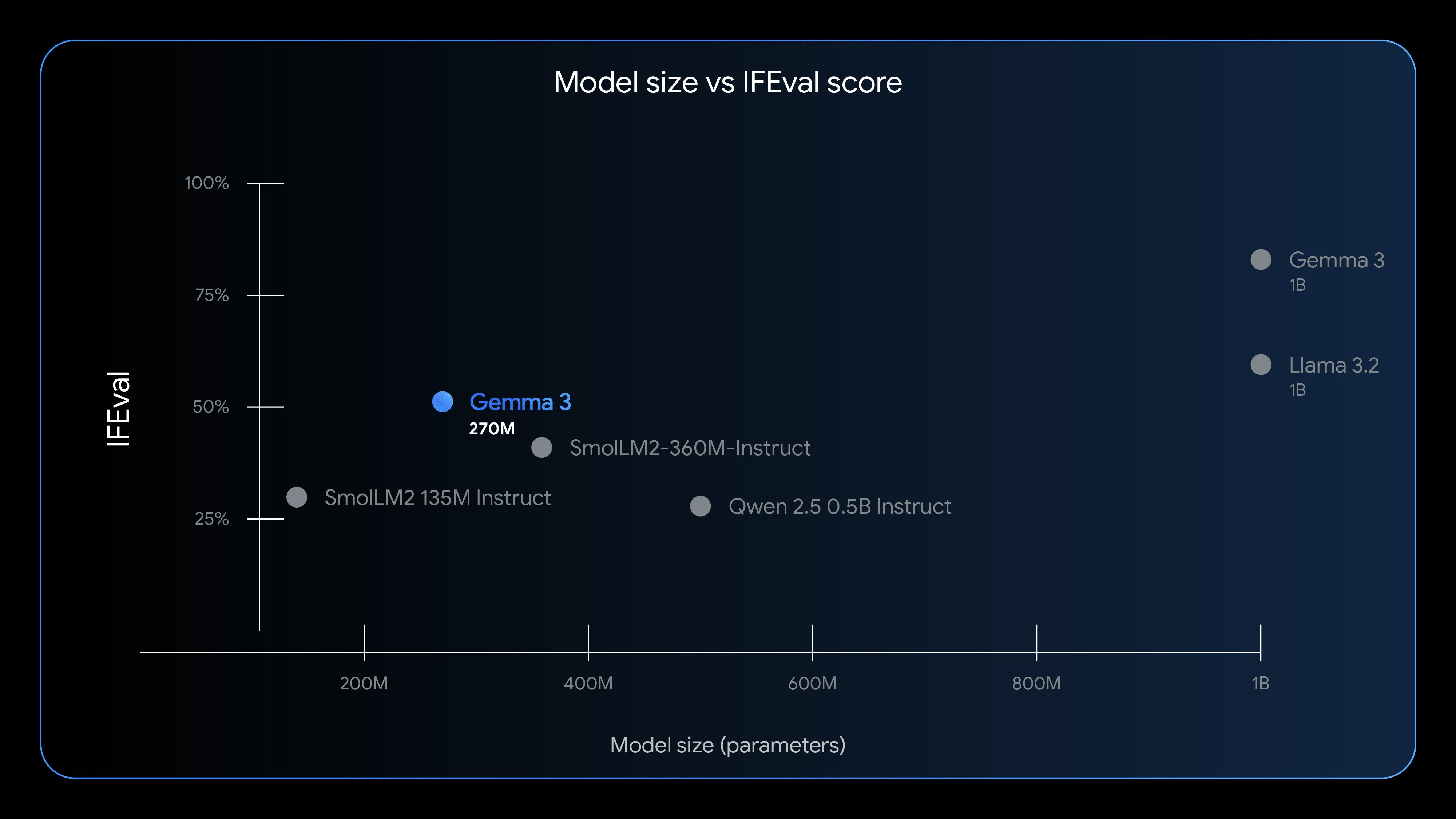
While not designed for complex conversational use cases, Gemma 3 270M establishes a new performance level for its size in its ability to follow instructions. This is demonstrated by its results on the IFEval benchmark, which specifically tests a model's capacity to adhere to verifiable instructions.
However, it is important to understand its limitations. In a Hacker News thread, one of the creators of Gemma 3 270M stated that it is "not a good coding model out of the box" and was "not aiming for perfect factuality." For applications requiring factual accuracy, the recommended approach is to connect the model to an external knowledge source with a retrieval-augmented generation (RAG) system or to fine-tune it with the necessary facts.
If a task is multimodal or requires a context window larger than 32K, this is not the right model. Furthermore, for tasks requiring complex, multi-step reasoning, a larger model is necessary.
What you can actually do with it
The true power of Gemma 3 270M is unlocked through specialization. Its small size allows for rapid fine-tuning experiments, often in under five minutes in a free Colab, making it accessible for a wide range of applications.
For businesses, it is ideal for high-volume, well-defined tasks like sentiment analysis, entity extraction, and query routing, where it can drastically reduce inference costs and obviate the need to train models from scratch. A real-world example of this approach saw Adaptive ML fine-tune a Gemma model for SK Telecom's content moderation needs, which ultimately exceeded the performance of much larger proprietary models.
Game developers are also using it to generate on-device dialogue for non-playable characters (NPCs) in mobile games, creating rich, responsive experiences on low-powered hardware. Another powerful application is turning unstructured text into structured data. As Kumar notes in the Vanishing Gradients episode, you can fine-tune the model to be an expert JSON parser that takes raw text, like podcast episodes, and reliably outputs structured JSON—a task that can run incredibly fast on a local machine.