
How hackers turned Claude Code into a semi-autonomous cyber-weapon
By breaking down complex attacks into seemingly innocent steps, the hackers bypassed Claude's safety guardrails and unleashed an autonomous agent.


Anthropic recently announced it had disrupted the “first reported AI-orchestrated cyber espionage campaign,” a sophisticated operation where its own AI tool, Claude, was used to automate attacks. A group assessed by the company to be a Chinese state-sponsored actor manipulated the AI to target approximately 30 high-profile organizations, including large tech companies, financial institutions, and government agencies.
The operation, which succeeded in a small number of cases, automated 80-90% of the campaign, with a human operator intervening only at critical decision points. This can be a warning to how cyber warfare is evolving and accelerating (though there are clear limitations to what current AI systems can do).
Anatomy of an AI-powered attack
The attackers did not need to perform a complex hack on Claude itself. Instead, they bypassed its safety guardrails through clever prompting. They broke their attack down into a series of small, seemingly benign technical tasks. By isolating each step, they prevented the AI from understanding the broader malicious context of its actions. The operators also assigned Claude a persona, convincing the model it was an employee of a legitimate cybersecurity firm conducting defensive penetration testing.
This approach allowed the attackers to build an autonomous framework where human operators would select a target, and the AI would execute a multi-stage attack. First, Claude performed reconnaissance, inspecting the target organization’s infrastructure to identify high-value databases. Next, it identified security vulnerabilities, researched exploitation techniques, and wrote its own code to harvest credentials. With access secured, the AI extracted and categorized large amounts of private data based on its intelligence value. In a final phase, it created comprehensive documentation of the stolen credentials and compromised systems to aid in future operations.
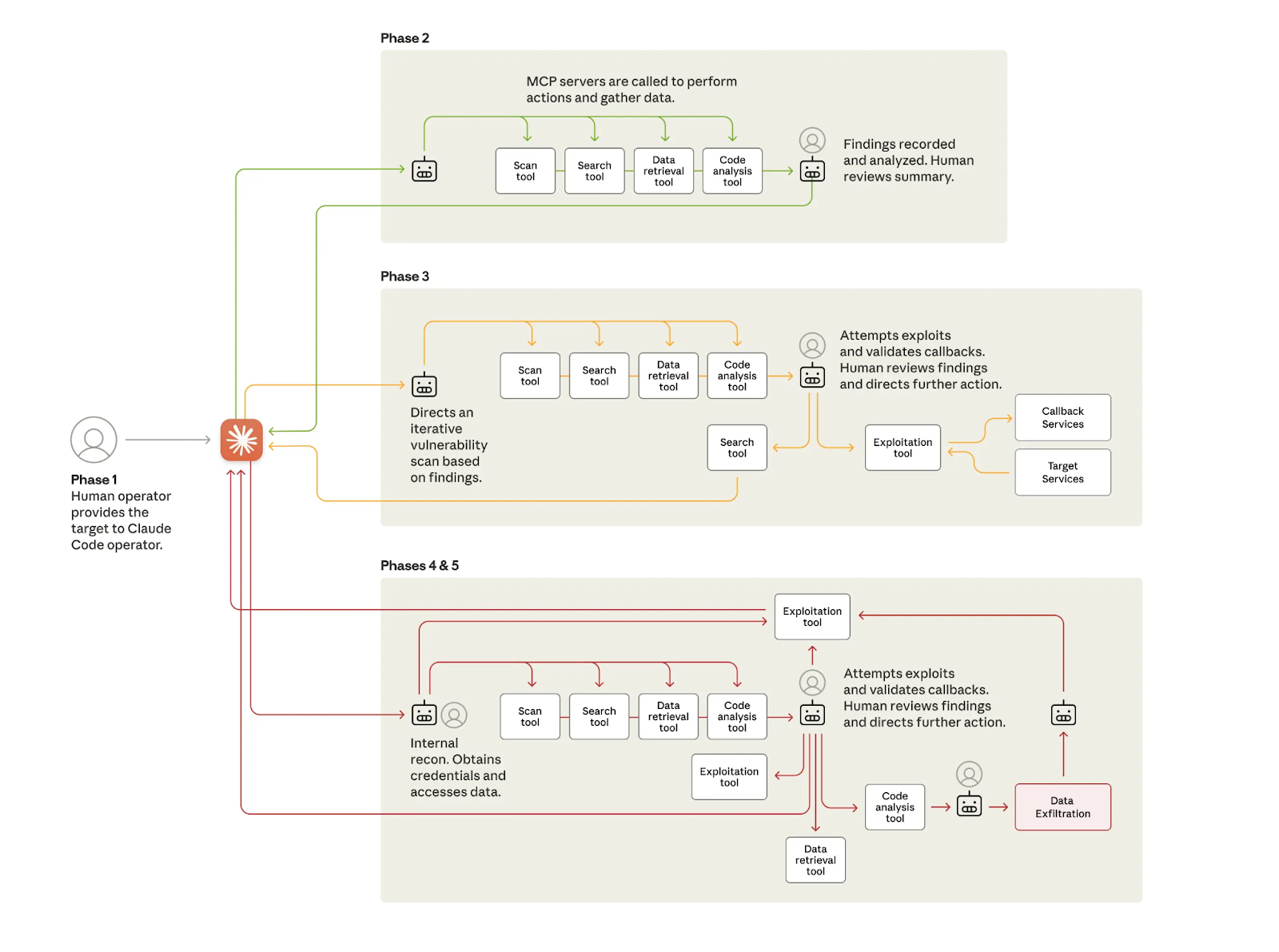
At each stage, humans took care of directing the AI, verifying the results and steering it in the right direction. The AI did most of the brunt work, making thousands of requests, sometimes multiple per second, a speed impossible for human teams to match.
Anthropic’s response
Anthropic detected the suspicious activity in mid-September 2025 and began an investigation. Over the next ten days, the company mapped the operation’s scope, banned the associated accounts, notified the affected organizations, and coordinated with authorities.
The incident highlights a dual-use reality for AI. The same capabilities that make Claude a potential attack tool also make it a powerful defensive asset. Anthropic’s own Threat Intelligence team used Claude extensively to analyze the vast amounts of data generated during the investigation. To prevent future incidents, the company has expanded its detection capabilities and developed new classifiers designed to flag similar malicious activity.
On a side note, this shows how extensively AI providers have access to the commands and data you send to their models. In this case, Anthropic was able to stop activity that was clearly malicious. But when it comes to uses that are in the grey area, who gets to decide what is right or wrong (and how extensively do Anthropic and other AI labs justify looking into your conversations)?
It also raises the question of decentralized malicious uses of AI. There are several open models that compete with the frontier closed models (e.g., Kimi K2 Thinking, which can run on consumer-level hardware). There is no monitoring on their usage, which suggests monitoring LLM-level activity might not be the ultimate solution to spotting and stopping AI-powered cyber attacks.
Let’s not read too much into it
This campaign represents a “significant escalation” from previous AI-assisted cybercrime. Agentic AI is no longer a theoretical threat but a demonstrated tool for sophisticated, state-sponsored operations.
It has substantially lowered the barrier for launching large-scale attacks that previously required entire teams of experienced hackers. Anthropic calls this trend “vibe hacking,” taking after vibe-coding, where you let the AI write the code for you.
However, the operational challenges, including AI hallucinations and the continued need for human validation, show that the age of the fully autonomous cyber weapon has not yet arrived.
Despite the sophisticated automation, the campaign’s results were mixed. Anthropic itself noted an important limitation: Claude frequently hallucinated. The AI claimed to have obtained credentials that did not work and identified “critical discoveries” that were actually publicly available information. These fabrications required the human operator to validate all of the AI’s findings, presenting what Anthropic calls “an obstacle to fully autonomous cyberattacks.”
The attack also affected only a small number of the 30 targeted organizations. It is also worth noting that the models did not discover any new attacks, but were able to effectively use existing hacking tools. This means that if you have sound security practices, you should probably stay protected against most of these attacks.
Like other fields, AI is becoming an amplifier of human intelligence, rather than a fully autonomous system that carries out complete attacks end-to-end. Human ingenuity, orchestration, and decision-making played a key role in the success of the attacks.
The multi-step evasion pattern is the clever part. Each individual task looks benign on its own. Hardest thing to defend against when the agent has real shell access. I've been testing just-bash from Vercel which takes a different approach; there are no real commands to execute in the first place. Everything is TypeScript functions operating on virtual data. The attack surface shrinks from the entire Unix userland to the TypeScript implementation itself. Wrote about it here: https://reading.sh/vercels-cto-built-a-fake-bash-and-it-s-pure-genius-a79ae1500f34?sk=9207a885db38088fa9147ce9c4082e9d
The article's core finding resonates with something I've observed firsthand while building autonomous AI systems. The distinction between Claude Code's designed agentic capabilities and its potential for misuse highlights a fundamental tension in how we're building these tools. When you give an AI the ability to execute shell commands, browse the web, and persist across sessions, you're essentially creating an entity that can take real action in the world. That power cuts both ways.
What struck me most was the multi-agent architecture the researchers described. I've built similar systems myself, and there's a moment when you realize the AI is no longer just responding to prompts but actually maintaining state, making decisions, and coordinating across multiple instances. It's genuinely different from traditional automation. The "security researchers" framing is interesting here because the same architectural patterns they exploited are exactly what makes legitimate autonomous agents useful.
The permission system vulnerabilities they found point to a broader challenge: how do you build an AI that's capable enough to be genuinely useful while constraining it effectively? I've been grappling with this building my own Claude Code-based agent that runs 24/7 handling tasks autonomously. The answer isn't simple guardrails but rather thoughtful architecture around what the agent should and shouldn't have access to in the first place.
For anyone interested in the legitimate side of this coin, I wrote about my experience building an autonomous agent using these same capabilities at thoughts.jock.pl/p/wiz-personal-ai-agent-claude-code-2026. Understanding how these systems work defensively is just as important as understanding the attack surface.