
How MIT’s new framework solve LLM's memory barrier and 'context rot' problem
Brute-forcing larger context windows is hitting a mathematical wall. Recursive language model (RLM) solves "context rot" to process 10 million tokens and beyond.


Recursive Language Models (RLMs), a new framework developed by researchers at MIT CSAIL, provide a solution to the limited context window of large language models (LLMs). This approach enables models to process arbitrarily long prompts without incurring massive memory costs or requiring the models to undergo special training to extend their context windows.
RLMs treat long prompts as part of an external environment, allowing the LLM to programmatically examine, decompose, and extract snippets of the prompt. The system is designed to be compatible with existing models, serving as a drop-in replacement for standard inference frameworks. Experiments show that RLMs successfully handle inputs up to two orders of magnitude beyond model context windows and, even for shorter prompts, dramatically outperform the quality of base LLMs.
How recursive language models work
The concept behind RLMs draws inspiration from the way computers switch data from active and permanent storage. A computer’s RAM is limited and can only process a certain amount of data at any given time. To work around this, computers store large-scale data on a hard drive and only fetch small “chunks” into the fast main memory as needed.
RLMs apply this logic to the limited context window of LLMs by treating the text data as part of an environment that the model can interact with. Instead of forcing the entire document into the neural network’s context window, the RLM keeps the text outside the model and selectively retrieves only the necessary pieces when required.
Rather than loading the full prompt and documents directly into the model, the RLM loads them into a Read-Eval-Print Loop (REPL) environment powered by Python. The LLM receives “general context” about the data, such as the total length of the string, but does not see the text itself initially.
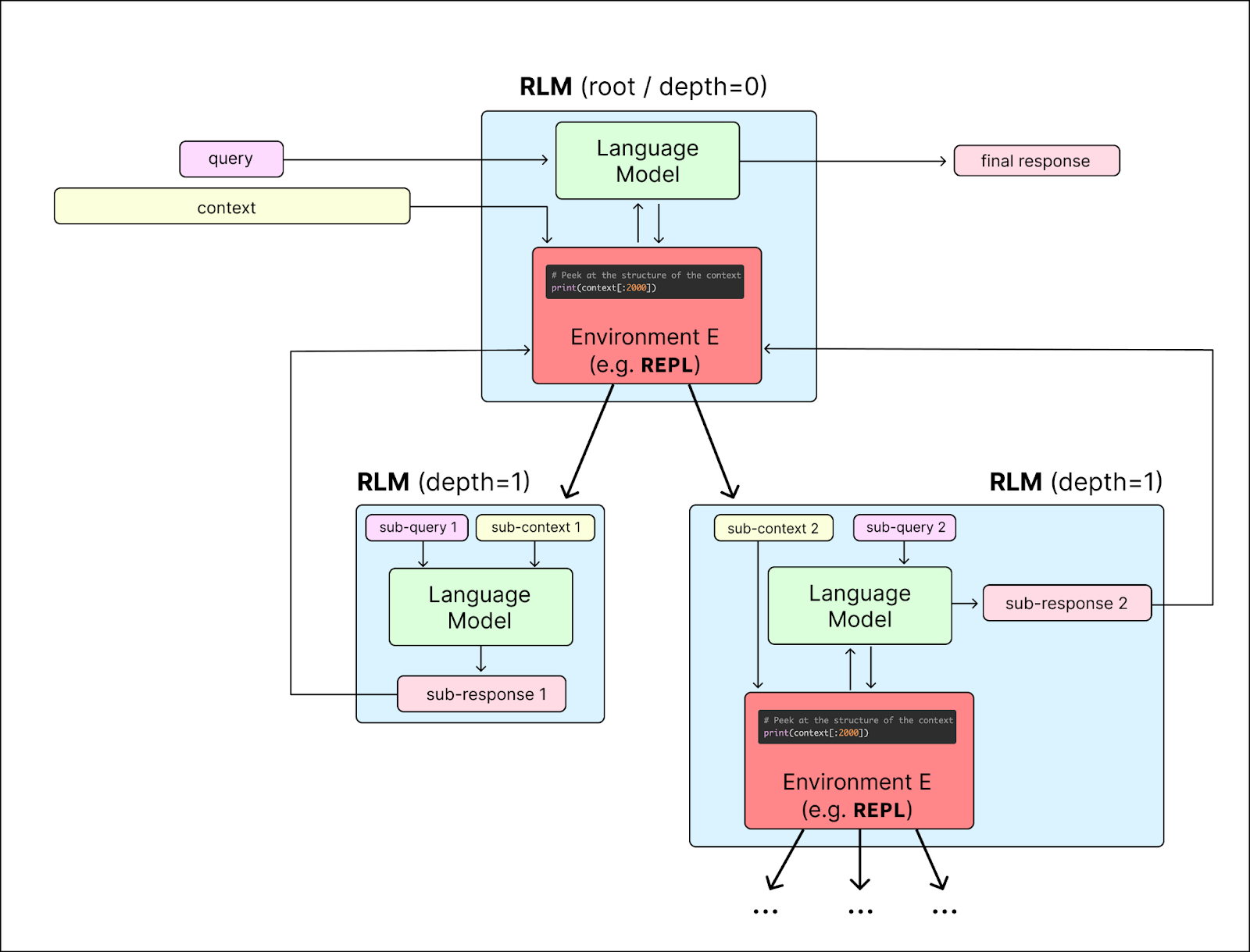
The LLM interacts with the document through coding commands. For example, it might check the first 500 characters to understand the format or use regular expressions to search for specific keywords like “festival” or “Chapter 1.” When the LLM finds a relevant snippet via code, it pulls that specific data into its active context window to analyze it and decide on the next steps.
This reliance on code generation means RLMs effectively require “reasoning” or “coding” grade models (e.g., GPT-5, Claude 3.5 Sonnet, or Qwen-Coder) to work reliably. Standard open-source models (like Llama 3 8B) would likely struggle to navigate the Python environment without specific distillation or fine-tuning.
The framework is called “recursive” because it enables the model to write code that can call itself to process specific chunks of the data. If the prompt is a long book, the LLM might write code to split the book into chapters. Then, inside a loop, it can recursively call a query on each chapter individually to summarize it.
Although the RLM is designed to be interacted with like any other LLM, it is composed of multiple models under the hood to maximize efficiency. The architecture typically includes a “root language model” that is powered by a strong LLM such as GPT-5 or Gemini 3. This root model acts as the orchestrator, interacts with the user, plans the solution, and sends commands to the REPL environment. Then there is the “recursive LM,” which is usually a smaller, faster model (e.g., GPT-5-mini) acting as the worker. The recursive LM is called by the root LM’s code to process specific “chunks” or snippets of the text. For example, it can summarize the chunks of text retrieved from the full prompt.
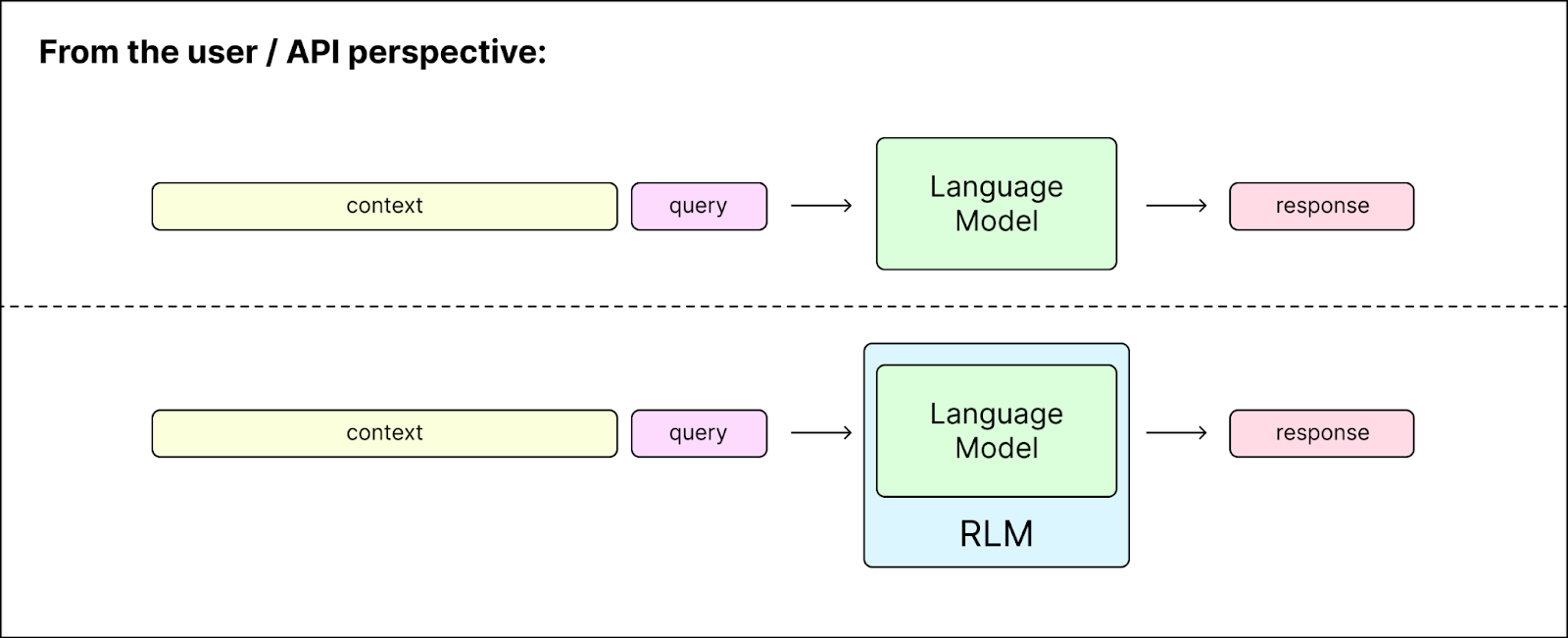
Because the prompt is stored in the environment’s memory rather than the model’s active context window, the model can handle inputs orders of magnitude larger than its training limit, such as processing 10 million tokens on a model technically limited to 272k. Notably, the RLM looks and behaves exactly like a standard LLM to the user. It accepts a string prompt and returns a string answer, allowing users to swap a standard model for an RLM without changing their code or workflow.
This approach represents a natural evolution from prompt engineering to optimizing how models manage their own memory. The code for RLM is currently available on GitHub. researchers plan to integrate RLMs directly into DSPy, a popular framework for programming language models.