
How reinforcement learning changed LLM tool-use
A look at the evolution of LLM tool-use, from supervised fine-tuning to Reinforcement Learning (RLVR) and agentic applications in large and specialized models.


Tool-use has been an important part of the development of large language models (LLMs) since the release of ChatGPT in 2022. Tools enable LLMs to interact with their environment and access information that goes beyond their internalized knowledge.
With AI agentic applications getting the spotlight in 2025, we’ve seen much impressive progress in both tooling, frameworks, and LLMs that can interact with their environment. Newer models are trained with native tool-use abilities. The release of Model Context Protocol (MCP) in late 2024 and other standards such as A2A and Claude Skills in 2025 made it easier to connect agents to tools and each other. And we’ve seen new specialized frameworks and models that can help enhance tool-use in AI applications.
Here is my brief take on the history of LLM tool-use, advances in 2025, and what to expect in the future.
The early innings of LLM tool-use
Between 2023 and 2024, researchers focused on teaching models how to call tools, primarily through supervised fine-tuning (SFT) on static data or basic feedback loops. 2023 established the “grammar” of tool use. Toolformer, released by Meta AI in February 2023, pioneered self-supervised tool learning. The model, based on the open-source GPT-J, learned to map inputs to API calls through labeled examples.
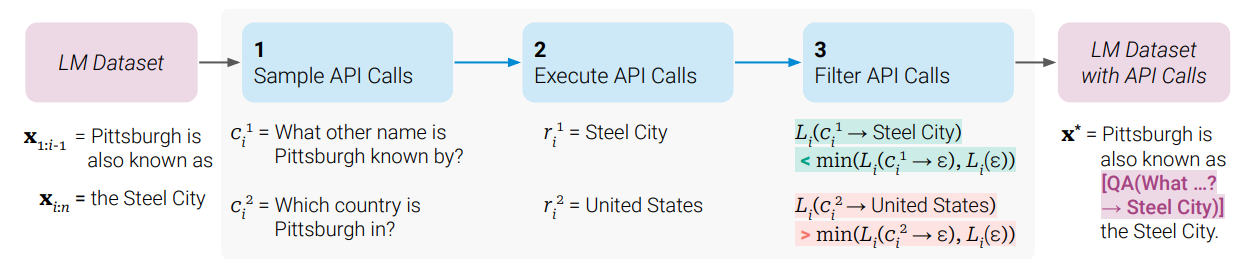
Gorilla, released in May 2023 by UC Berkeley and Microsoft Research, moved toward syntax-aware SFT, ensuring API calls matched “golden formats” like Abstract Syntax Trees. Gorilla was based on Llama-7B and was trained to support both zero-shot and in-context API calls. At the time, it outperformed frontier models such as GPT-4 and Claude in remaining faithful to API syntaxes and avoiding hallucinated function calls and formattings.
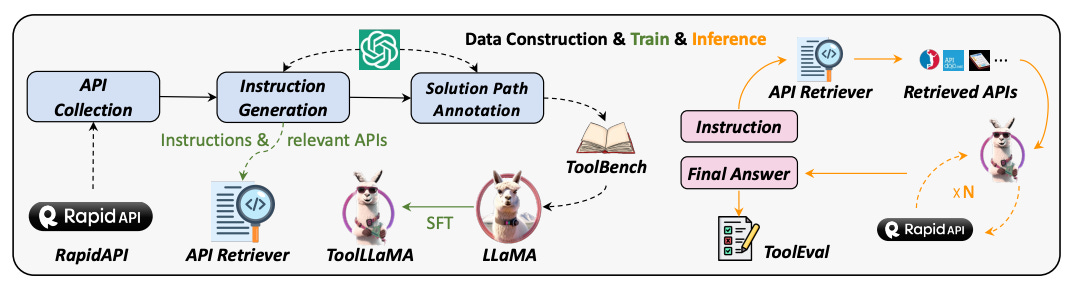
ToolLLM (Oct 2023) scaled this up, teaching Llama to master thousands of real-world APIs via instruction tuning.
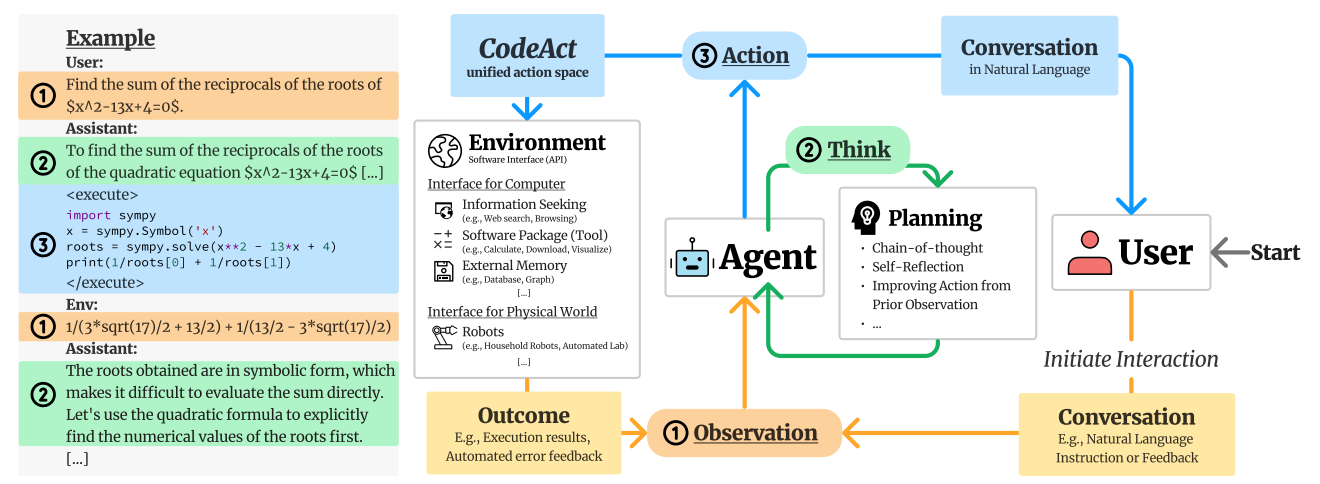
In 2024, the focus shifted to executable environments. CodeAct (Feb 2024) by University of Illinois Urbana-Champaign and Apple replaced text APIs with executable Python code, using execution success as a training signal. The model was trained using direct execution feedback (success/failure signals) from a code sandbox, integrating the results in its reasoning chain and grounding its learning in verifiable outcomes. This set the stage for more complex agentic tasks.
DeepSeek-Prover-V1.5, released in August 2024, introduced reinforcement learning (RL) into formal theorem proving, generating multiple proof candidates and using a proof verifier as a reward signal. This set the stage for the explosion of RL-based methods in 2025.
Reinforcement learning for agentic tool-use
By 2025, tool-use had become an integral part of the training of every frontier LLM. Models such as GPT-5, o3, Gemini 2.5 and 3, and the latest Claude models are trained for agentic tasks, by having native tool-calling support and being adaptable to new tools through few-shot examples.
At the same time, published research showed a shift toward more use of reinforcement learning with verifiable rewards (RLVR) and more advanced tool adaptation strategies. Researchers began optimizing agents using direct environment feedback or final answer correctness while simultaneously developing sub-agents to serve as specialized tools for frozen models.
DeepSeek-R1, released in January 2025, set much of the tone for the year by showing how far RLVR could take LLMs. DeepSeek-R1 used RLVR with a reward signal that was derived directly from the execution output of generated code (e.g., passing unit tests). It established the standard for using verifiable execution outcomes to drive policy optimization.
Search-R1, released in March 2025, used RL to train an LLM (Qwen-2.5) to generate multi-step search and reasoning steps. At inference, Search-R1 interleaves its chain-of-though (CoT) with real-time search engine interactions, enabling it to update its reasoning as more information becomes available and refine its queries. This is especially useful for tasks where the model doesn’t have enough knowledge and needs to reason in multiple steps.