
How Samsung's Tiny Recursive Model outsmarts giant LLMs on complex puzzles
The Tiny Recursive Model proves "less is more," allowing a simple two-layer network to master complex logic puzzles that stump even the largest AIs.


Researchers at Samsung AI Lab have designed a new neural network architecture that shows remarkable efficiency on complex reasoning tasks, outperforming popular large language models (LLMs) while using a tiny fraction of the computational resources.
Called the Tiny Recursive Model (TRM), the new architecture builds on the success of a recently proposed Hierarchical Reasoning Model (HRM) and refines its approach to solve some of its inefficiencies. Experiments show that TRM outperforms both HRM and classic LLMs on hard puzzle tasks like Sudoku and ARC-AGI with less than 0.01% of the parameters of its larger counterparts.
Hierarchical Reasoning Model (HRM)
When faced with complex reasoning problems, LLMs often rely on techniques like chain-of-thought (CoT) prompting, where they generate step-by-step reasoning traces before giving a final answer. While this can improve accuracy, CoT is expensive, requires high-quality reasoning examples for training, and is brittle if the model generates a single incorrect step. Another range of techniques, usually referred to as test-time compute (TTC) or test-time scaling, involve generating multiple answers and picking the most common one, further increasing the computational cost. Even with these methods, LLMs still struggle with certain hard reasoning tasks.
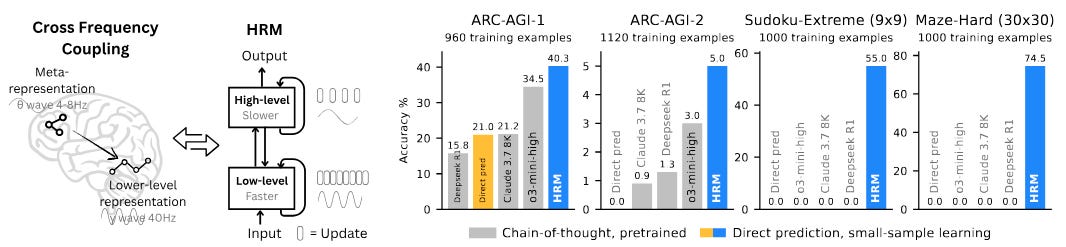
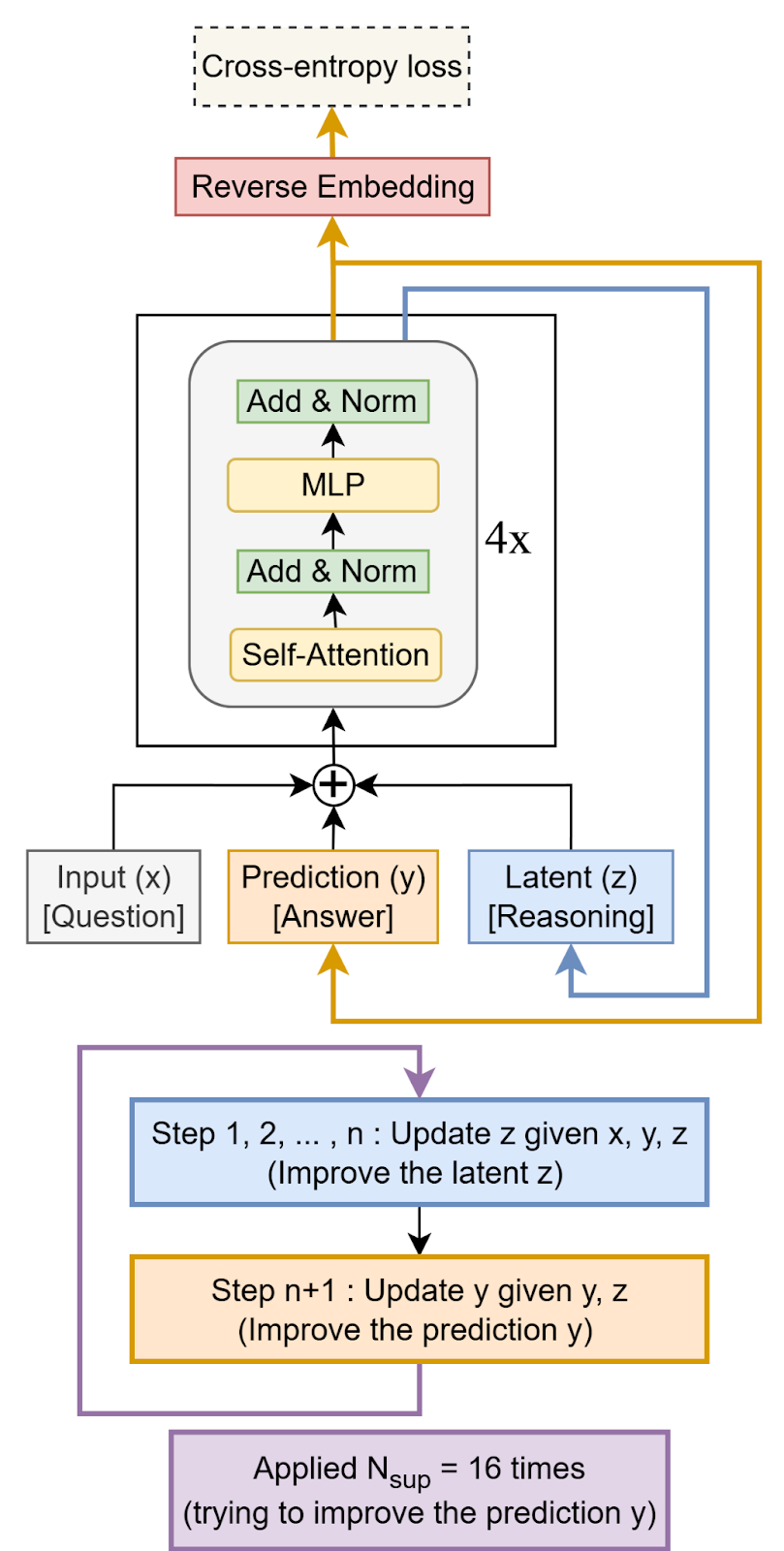
As an alternative, the Hierarchical Reasoning Model (HRM) was recently introduced. HRM uses two small networks that operate at different levels (hence the “hierarchical” in the name) and leverages a technique called deep supervision, which reuses the model’s past computations to adjust and course-correct its reasoning process. This process allows the model to iteratively improve its answer over multiple steps, much like a person reviewing their work to catch errors. This recursive approach enables HRM to simulate the reasoning depth of a much larger network without needing to backpropagate through all the layers, which is computationally intensive. The result is a model that achieves high performance on hard puzzle tasks where other models fail. The creators of HRM took inspiration from human and animal brains to design HRM.
However, an independent analysis by the ARC Prize Foundation suggested that the key to HRM’s success wasn’t its complex hierarchical structure but rather the iterative improvement from deep supervision. This finding implied that repeatedly refining an answer is beneficial, but the specific recursive method used in HRM might be overly complicated. As the paper notes, “This suggests that reasoning across different supervision steps is worth it, but the recursion done in each supervision step is not particularly important.”
Less is more with the Tiny Recursive Model
Building on this insight, the Samsung researchers developed the Tiny Recursive Model. TRM is a simplified and improved approach that uses a single, tiny two-layer network to achieve significantly better generalization than HRM on a variety of problems.
Unlike HRM, TRM does away with complex biological arguments, hierarchical structures, and the need for fixed-point mathematical theorems to justify its architecture. It streamlines the process by using just one network instead of two and a more efficient halting mechanism that requires only one forward pass instead of two. This makes the entire model simpler and faster.
During development, the team attempted to scale the model by adding more layers, a common practice for increasing a model’s capacity. Surprisingly, they found that adding layers hurt performance due to overfitting. In contrast, by reducing the number of layers from four to two while proportionally increasing the number of recursive steps, they discovered a sweet spot that maximized generalization. This “less is more” approach allowed a very small model to perform deep reasoning without being unnecessarily complex.
TRM in action
The researchers tested TRM on several difficult benchmarks, including Sudoku-Extreme, a set of very hard 9x9 Sudoku puzzles; Maze-Hard, which involves finding long paths in 30x30 mazes; and ARC-AGI, a set of geometric reasoning puzzles designed to be easy for humans but difficult for AI.
On Sudoku-Extreme, the 5M-parameter TRM achieved 87.4% accuracy, a massive improvement over HRM’s 55.0% and far beyond LLMs like Deepseek-R1, which scored 0.0%. On Maze-Hard, a 7M-parameter TRM with self-attention layers reached 85.3% accuracy, compared to 74.5% for the 27M-parameter HRM. On the challenging ARC-AGI-1 and ARC-AGI-2 benchmarks, the same 7M-parameter TRM scored 44.6% and 7.8% respectively, surpassing HRM and most LLMs, some of which are over 100,000 times larger. For example, the 1.7-trillion parameter Grok-4 model achieves higher scores, but TRM demonstrates what is possible with drastically fewer resources.
The results also revealed interesting architectural nuances. A version of TRM using simpler MLP layers performed best on the structured Sudoku task, while a version with self-attention was better for tasks with larger and more variable contexts like Maze-Hard and ARC-AGI.
“Overall, TRM is much simpler than HRM, while achieving better generalization,” the researchers write.
In the AI realm every day we reinventing the hot water