
How SLMs can beat large models at reasoning tasks
Hugging Face has a recipe for turbocharging small models at tasks that require planning and reasoning.


With so much buzz around large reasoning models (LRMs) such as OpenAI o1 and o3, there is a lot interest in recreating their success. In a new case study, researchers at Hugging Face demonstrate how small language models (SLMs) can be configured to outperform much larger models at specific tasks.
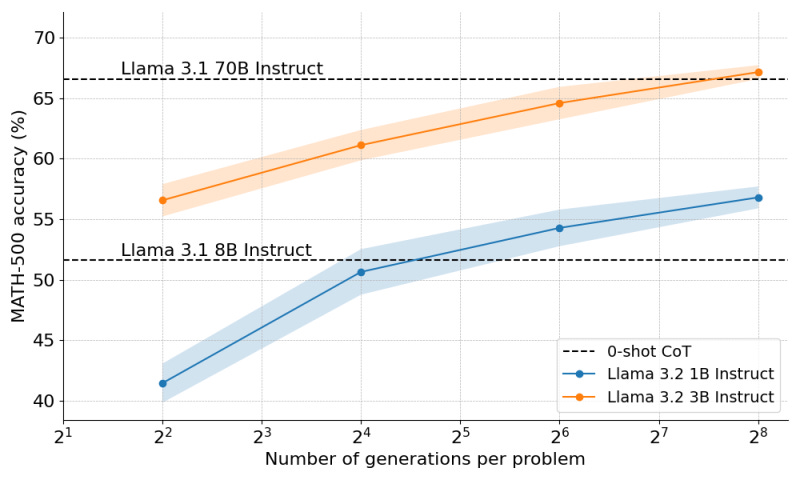
According to their findings, a Llama 3 model with 3 billion parameters can outperform the 70B version of the model in complex math problems.
Hugging Face work is based on a DeepMind study that explores the tradeoffs between inference-time and pre-training compute.
The technique has three key components: using extra inference compute cycles to generate more answers, a reward model that evaluates the answers, and a search algorithm that optimizes the path it takes to refine its answers.
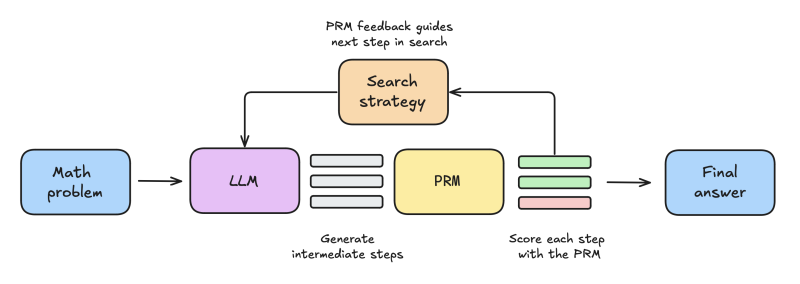
During inference, the SLM generates multiple answers and uses a “process reward model” (PRM) to score the answers based on the final token as well as the reasoning process. This combination outperforms the classic “majority voting” inference technique, which only evaluates answers based on the number of times they recur.
To further refine the technique, the researchers added a variant of the beam search algorithm, which helps the model better choose its answers. Basically, instead of having the model generate N answers, this technique prompts the model to generate N/K partial answers, chooses the most promising paths and prompts the model to further complete those answers. This way, instead of wasting its compute budget on generating a lot of useless answers, it focuses its efforts on building a tree of good answers.
The combination of these techniques enabled Llama-3.2 1B to punch above its weight and outperform the 8B model by a significant margin. They also found that the strategy was scalable, and when applied to Llama-3.2 3B, they were able to outperform the much larger 70B model.
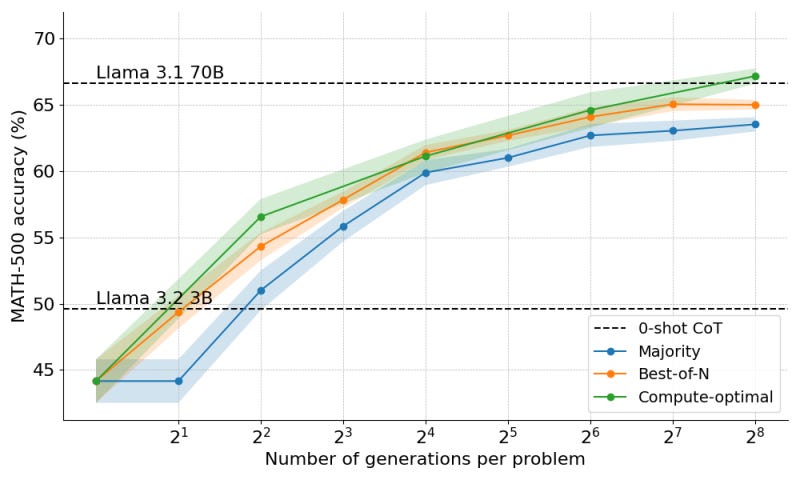
This is not a perfect solution. For example, the researchers used a specially trained Llama-3.1-8B model as the PRM, which requires running two models in parallel. The holy grail of test-time scaling is to have “self-verification,” where the original model verifies its own answer as opposed to relying on an external verifier. This is an open area of research.
The technique is also limited to problems where the answer can be clearly evaluated, such as coding and math. Creating reward models and verifiers for subjective tasks such as creative writing and product design requires further research.
Nonetheless, it’s an interesting area to keep watching in the coming months.