
How sparse attention is solving AI's memory bottleneck
As AI agents take on longer tasks, the KV cache of LLMs has become a massive bottleneck. Discover how sparse attention techniques are freeing up GPU memory.


LLMs are getting pulled into longer and messier workflows, handling large inputs and generating longer and longer token sequences. Coding assistants need to keep track of repositories, issue threads, terminal outputs, and earlier edits. Research agents need to carry facts across long documents and tool calls. Deep think systems may generate several parallel chains before settling on an answer.
All of that means more tokens in memory, and more time spent attending to past tokens. In practice, that pushes modern models into a bottleneck that is less about raw model size and more about how they store and read attention state. That state is the key-value cache, or KV cache. It is one of the reasons autoregressive generation is fast enough to be usable at all, but it is also one of the main reasons long-context inference gets expensive and slow.
Recent research shows that if you want better long reasoning and multi-agent workflows, you need to address the attention memory bottleneck and optimize attention while preserving accuracy. And this focus has led to some very interesting “sparse attention” techniques.
Why attention becomes a memory problem
In transformer models, each new token is processed by attention layers that compare the current token’s query vector against key vectors from earlier tokens, and then combine the corresponding value vectors. In autoregressive generation, the model creates text one token at a time, so it would be wasteful to recompute keys and values for the entire prior sequence at every step. Instead, it stores them in the KV cache and reuses them.
This method of calculating and storing all attention values (aka “dense attention”) creates a quadratic compute and memory tax. Dense causal attention means each new token can attend to all prior tokens, so the work grows rapidly with sequence length.
But compute is only part of it. The KV cache grows linearly with the number of generated tokens, it sits in GPU VRAM, and reading it from high-bandwidth memory can dominate runtime during generation. At larger sequence lengths and batch sizes, the latency contribution from KV cache reads becomes the dominant term. That is why long prompts and long outputs slow systems down even when the model architecture itself has not changed.
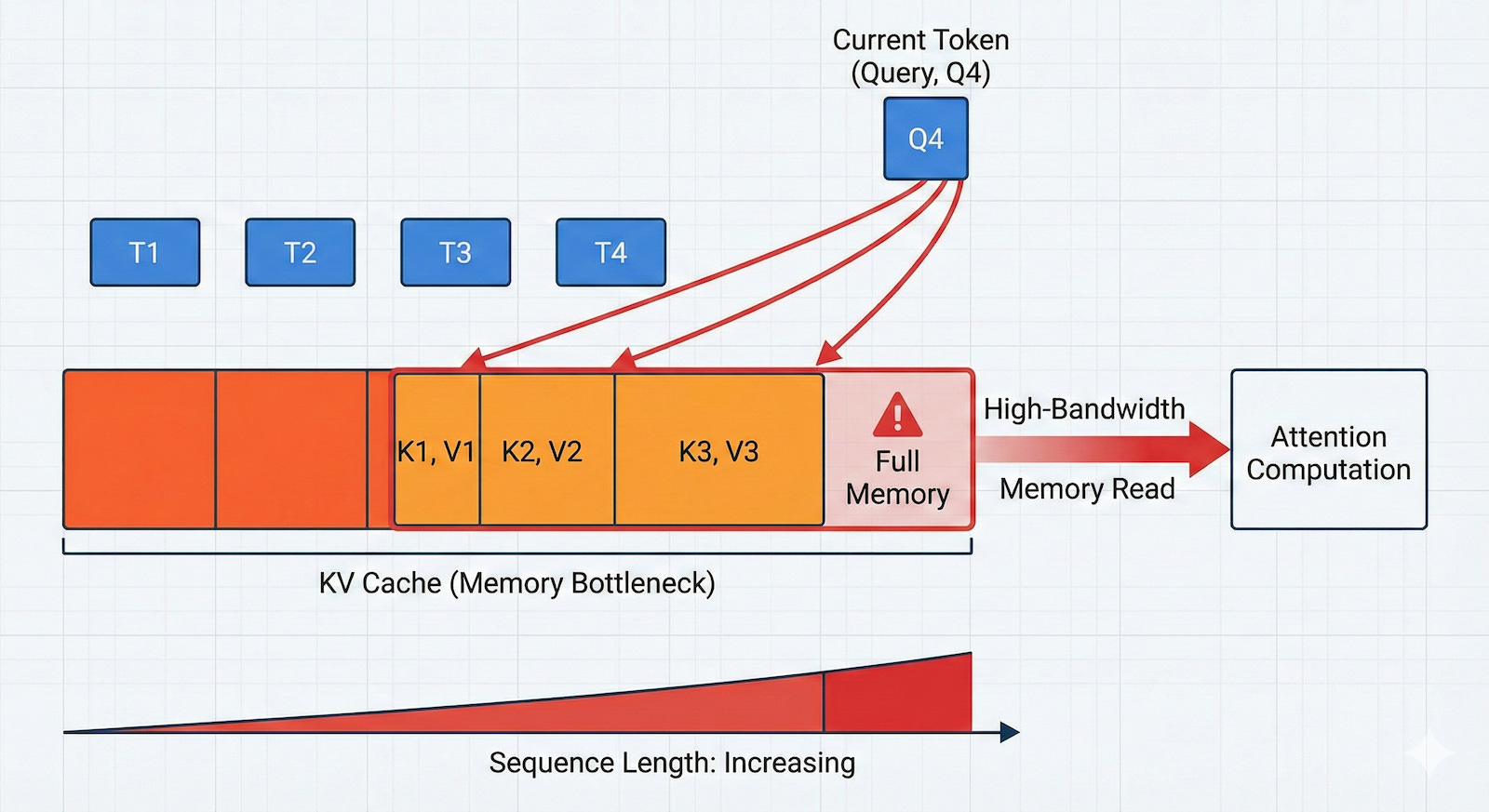
It is also worth noting the difference between “prefill” and “decode,” which matters a lot for application behavior. Prefill is the first pass over the prompt, where the model processes the input tokens and fills the KV cache. Decode is the token-by-token generation loop that follows, where each new token reads from that cache. Many optimizations help decode more than prefill. The challenge of processing all the input tokens (documents, in-context learning examples, etc.) and storing attention values remains unsolved.
The basic idea behind sparse attention
Sparse attention starts from a simple observation: most tokens in a long sequence are not equally useful for every next-token decision. If a model can identify which past tokens matter for the current query token, it can avoid reading and scoring the full history. That cuts memory movement and compute.
There are different ways to make attention sparse. Some methods permanently remove (or “evict”) tokens from the cache. Some keep the cache but retrieve only a subset of pages or blocks. Others change the architecture so fewer layers rely on full self-attention. The common goal is the same: reduce the amount of attention values that the model must carry and touch at inference time.
A simple method is “sliding-window attention,” which keeps a fixed number of tokens in the KV cache. As the model’s context grows, the sliding window evicts older tokens to free space for new ones.
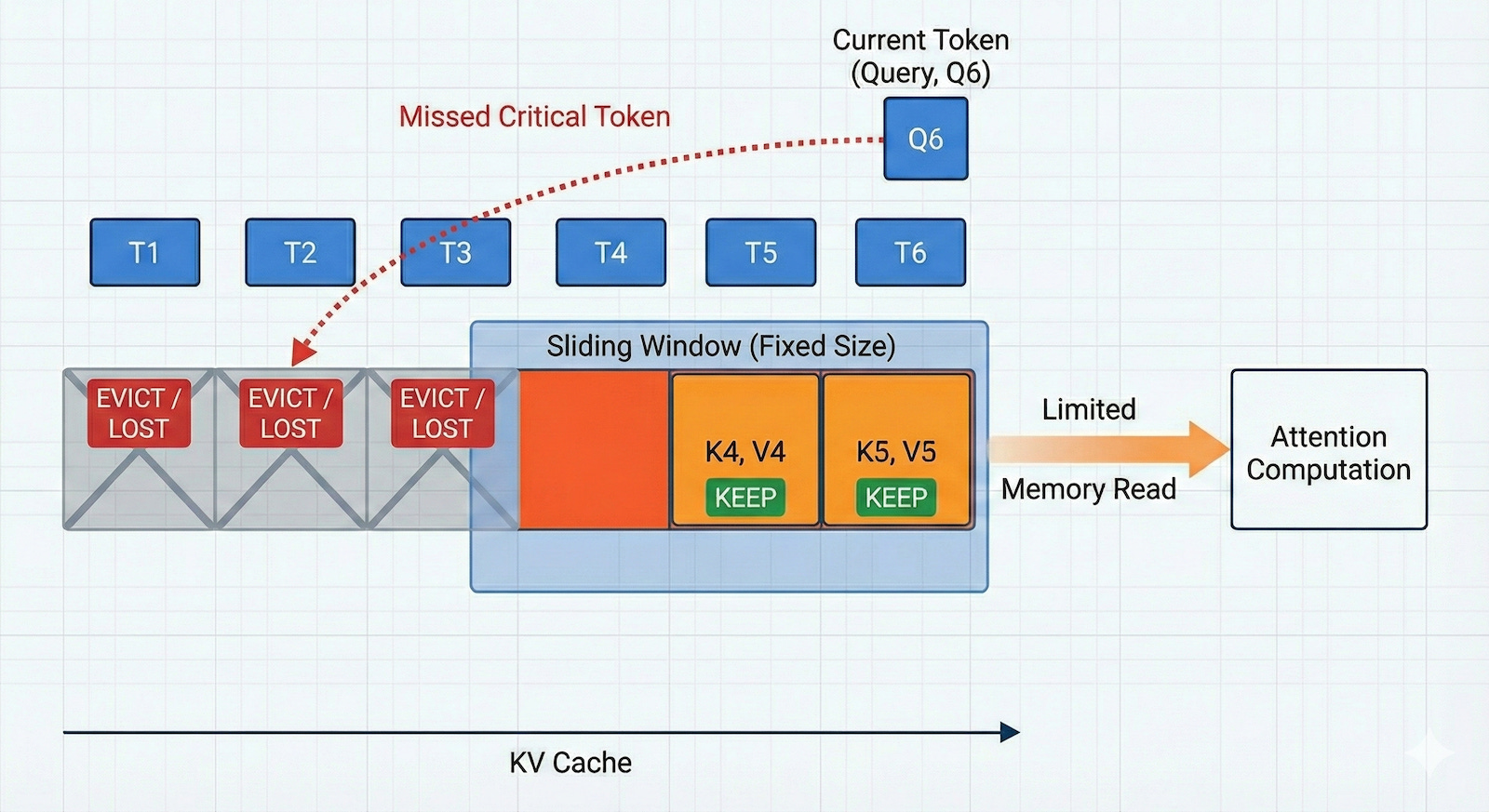
Other early techniques lean on heuristics to evict tokens. For example, Token Omission via Attention (TOVA) drops tokens based on attention values. TOVA looks at the current step and checks which tokens attention heads are focusing on. It keeps the top-ranked tokens and deletes the rest. TOVA assumes that if a piece of information isn’t relevant to the current thought process, it won’t be needed later. Heavy-Hitter Oracle (H2O), another heuristics-based method, tracks which tokens have been paid attention to frequently over time. It assumes that important concepts (like a character’s name in a story or a variable x in code) will be looked at repeatedly. It keeps these important tokens, which it calls “Heavy Hitters,” and a sliding window of the most recent attention values, evicting everything else.
These methods can be fast and easy to deploy, but they tend to hit a wall when compression becomes aggressive. The key issue is information loss. If a system drops a token too early, later steps cannot recover it. That hurts exact retrieval, long-range dependencies, and multi-step reasoning. Also problematic is that most LLMs use Grouped Query Attention (GQA), where multiple query heads share a single block of memory to save space. Standard eviction methods often delete a piece of memory because one head isn’t using it, accidentally starving other heads that did need it.
Another method, Query-Aware Sparsity (Quest), keeps the cache but tries to retrieve only the most relevant blocks from memory. It groups tokens into fixed-size pages (e.g., blocks of 16 tokens). During the generation step, it uses a heuristic to estimate which specific pages contain relevant information for the current token being generated. It then copies only those pages from the GPU’s memory (HBM) to faster on-chip memory (SRAM). This makes it possible to better manage the scarce and expensive high-speed memory. Because the attention bottleneck is usually caused by moving data from memory to the chip, Quest speeds up generation significantly by moving less data. However, it does not solve “Out of Memory” (OOM) errors. In fact, Quest creates a slight memory overhead because it has to store additional metadata to manage the pages.
DeepSeek Sparse Attention (DSA)
DeepSeek Sparse Attention (DSA) is one of the more important recent ideas in this space because it tries to keep the efficiency gains of sparsity without the usual quality collapse. First used in DeepSeek-V3.2, the mechanism has two parts: a “lightning indexer” that scores relevance between the current query token and earlier tokens, and a token-selection stage that keeps a fixed number of top-scoring KV entries for full attention computation.
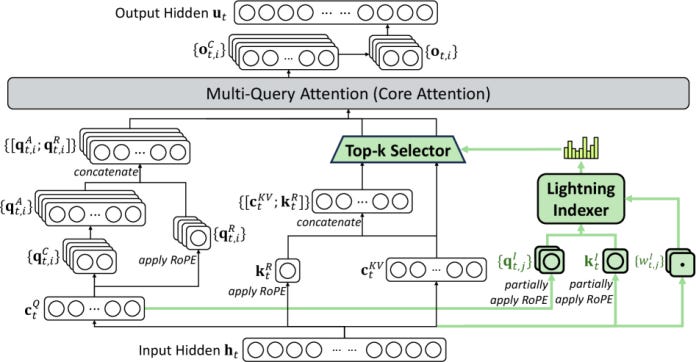
Unlike heuristics-based methods, DSA requires training, which means it cannot be plugged into any model out-of-the-box. The indexer is trained first, then adapts the model to the sparse pattern. The indexer warm-up runs for 1,000 steps with dense attention and frozen base weights, then the model switches to a sparse training stage where the model and indexer are trained together. During sparse training, DeepSeek selects 2,048 KV tokens per query token.