
How to create an optimal memory structure for LLM agents
A-MEM creates complex, structured memory notes that allows LLM agents to handle very complex tasks


A-MEM, a new framework proposed by researchers at Rutgers University, Ant Group, and Salesforce Research, enables LLM agents to create linked memory notes from their interactions with their environment.
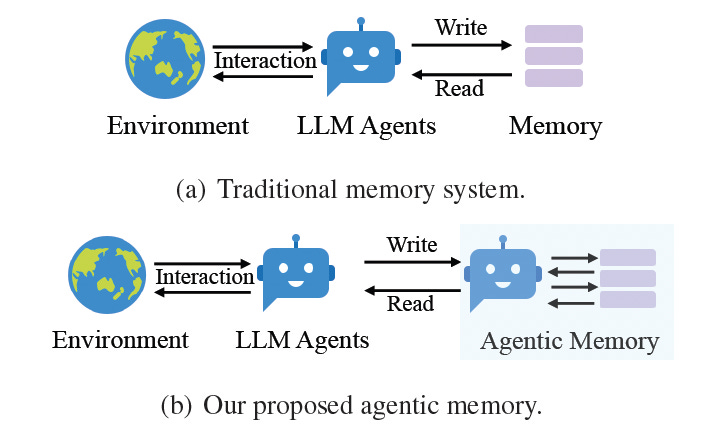
Memory is a key component of agentic LLM applications. Agents should be able to gather information from their environment and structure them into reusable memory objects. Current memory systems are too simple or based on predefined schemas, which do not make them suitable for the complex and changing nature of agentic applications.
A-MEM proposes a dynamic memory structure that flexibly adjusts to the interactions of agents with their environment.
How it works
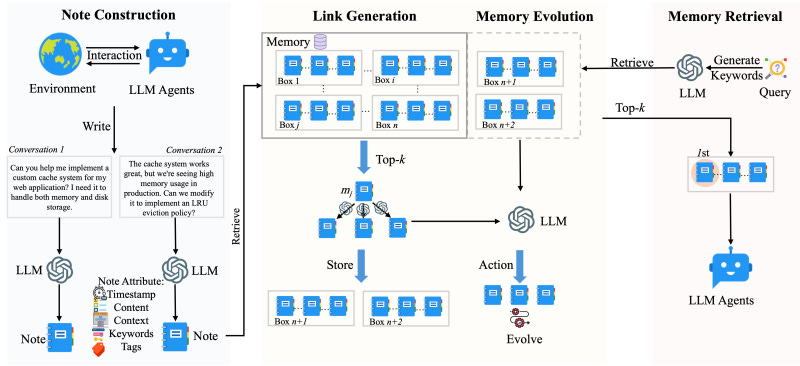
Every time an LLM agent interacts with its environment, A-MEM creates a “structured memory note” composed of the interaction data (e.g., document, chat message, etc.) and metadata such as time, contextual information, relevant keywords, and linked memories (more on this in a bit). The system uses an LLM to generate the contextual information and keywords.
A-MEM uses an encoder model (e.g., BERT) to create embedding values from the memory note. A-MEM uses a similarity search on the embedding values of the memory store to find candidate memories to link to the new note. It then uses an LLM to examine the full content of the candidates and choose the ones that are most suitable to link to the new memory.
This efficient, two-stage process of using embeddings and full content allows A-MEM to scale efficiently to millions of memory notes as the agent continues to interact with its environment. Once the links are established, A-MEM updates both the new memory and the existing linked memories. Over time, this enables the system to create a flexible knowledge structure that grows in complexity and adapts to the environment as the agent continues to interact and explore.
When the LLM agent makes a new interaction, A-MEM uses this context-aware retrieval mechanism (i.e., embedding search followed by context comparison) to find relevant memories and integrate them into the prompt. The added contextual and historical information enables the agent to have better awareness and knowledge of the task it is accomplishing.
A-MEM vs other frameworks
The researchers tested A-MEM on LoCoMo, a dataset of very long conversations that contain challenging situations such as multi-hop questions across multiple chat sessions, reasoning questions that require temporal understanding, and questions that require integrating contextual information from the conversation with external knowledge.
According to their experiments, A-MEM outperforms other memory frameworks such as LoCoMo, ReadAgent, and MemGPT, especially when using open source models. More importantly, A-MEM achieves superior performance while generating up to 10x fewer tokens when answering questions.
The code for A-MEM is available on GitHub.
On-the-fly learning and memory are one of the bigger remaining challenges for deployment of agents that can adapt without massive retraining. Glad to see such work