
How to customize LLMs without RAG
Just dump your documents into the prompt and cache the repetitive parts (with a few caveats)


Retrieval-augmented generation (RAG) is the main way of configuring LLMs for custom domains. However, RAG is limited by technical costs and speed limitations. Fortunately, with the context windows of LLMs becoming longer, developers can customize the models without using RAG.
A new study by the National Chengchi University in Taiwan suggests cache-augmented generation (CAG), an approach that uses long-context LLMs and caching techniques to replace RAG in simple settings where the knowledge corpus can fit in the model’s context window.
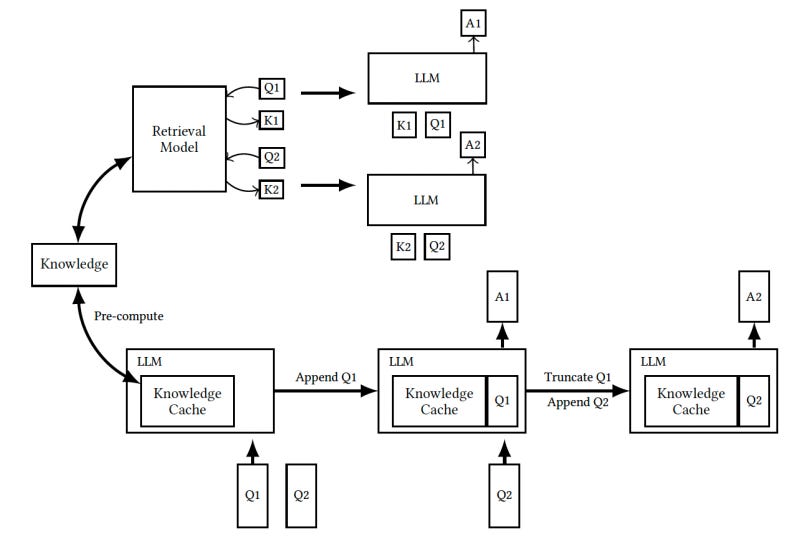
The alternative to RAG is to insert the entire knowledge corpus into the prompt and have the model choose which bits are relevant to the request.
However, this approach has three key challenges:
1- Long prompts slow down the LLM and increase inference costs.
2- The amount of information you can fit in the prompt is limited by the size of the LLM’s context window.
3- More importantly, many experiments show that adding irrelevant information to the prompt can confuse the model and reduce the quality of its answers.
CAG leverages three key trends to overcome these challenges:
1- Advanced caching techniques can precompute KV values to speed up inference. Since the documents and instructions section of the CAG prompt are constant, they can be cached. Most leading LLM providers have caching features that reduce costs and speed up inference.
2- Long-context LLMs make it possible to fit many documents into prompts (Claude supports 200,000 tokens, GPT-4o support 128,000 tokens, and Gemini supports up to 2 million tokens).
3- Advanced training methods are improving LLMs’ abilities to perform retrieval, reasoning, and question-answering on very long sequences.
As newer generations of models continue to expand their context windows, they will be able to process larger knowledge collections. Moreover, we can expect models to continue improving in their abilities to extract and use relevant information from long contexts.

The researchers compared CAG and RAG on SQuAD and HotPotQA, benchmarks for testing models on Q&A and multi-hop retrieval.
The setup:
Model: Llama-3.1-8B with 128k token context window
Sparse RAG configuration: LLM + BM25 retrieval
Dense RAG configuration: LLM + OpenAI embeddings
CAG: LLM + multiple documents inserted into the prompt (cached for performance boost)
Their experiments show that in settings where the corpus fits into the context window, CAG outperformed both RAG systems in most situations. CAG is also significantly faster as it eliminates the retrieval step.

Two things to consider when using CAG:
Don’t use it if your knowledge corpus changes dynamically (the costs of repeated caching would outweigh the benefits)
Use it carefully if your documents contain conflicting and context-dependent information
The best way to determine whether CAG is good for your use case is to run a few experiments. Fortunately, the implementation of CAG is very easy and should always be considered as a first step before investing in more development-intensive RAG solutions.