
How to prevent reasoning models from overthinking
Some prompts don't need one minute of thinking.


One of the key problems with reasoning models such as o1/o3 and R1 is that they treat every prompt as a hard problem that needs long thinking. But many (if not most) prompts don’t need chain of thought (CoT) reasoning and can be directly answered.
LLMs be able to tell when to use CoT and when to directly answer without wasting resources. “Inference Budget-Constrained Policy Optimization” (IBPO), a new technique developed by researchers at Meta AI and the University of Illinois Chicago trains models to allocate inference resources based on the difficulty of the query.

One of the main approaches used in reasoning models is “majority voting” (MV), where the model generates multiple answers and chooses the most popular one.
The researchers propose a series of techniques to improve the MV process.
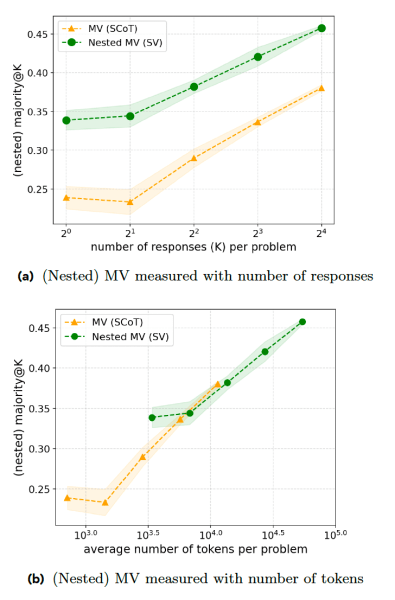
First is “sequential voting” (SV), which trains the model to stop the reasoning process if an answer is repeated a certain number of times. For example, the model is instructed to stop as soon as an answer shows up three times. This way, if the model is given a simple query (e.g., “What is 1+1”), the first three answers will probably be similar and stop the CoT early.
SV outperforms classic MV in math competition problems when generating the same number of answers. But it requires extra instructions and token generation, which almost cancels out the answer efficiency.
To further improve the process, the researchers suggest “adaptive sequential voting” (ASV), which teaches the model to only generate SV when the problem is difficult. For simple problems (such as the 1+1 prompt), the doesn’t go through the voting process and generates a single answer. Now, you have a model that is efficient at both simple and complex problems.
IBPO, the main technique they propose, improves the entire process by reducing the need for hand-labeled data, which is required for both SV and ASV. IBPO is a reinforcement learning (RL) algorithm that reaches the LLM to optimize its response for both accuracy and inference budget constraints.
During training, the model is prompted to generate ASV traces of different lengths. The responses are verified for both accuracy and inference optimization and used to retrain the model. Eventually, the model learns to choose the optimal reasoning process that meets both constraints.
Their experiments show that for a fixed inference budget, a model trained on IBPO outperforms other baselines.

This is the latest in a series of papers that show how reinforcement learning can produce results beyond the costly supervised fine-tuning (SFT) process, which has been the gold standard for quality training for a long time.
The researchers note that “prompting-based and SFT-based methods struggle with both absolute improvement and efficiency, supporting the conjecture that SFT alone does not enable self-correction capabilities. This observation is also partially supported by concurrent work, which suggests that such self-correction behavior emerges automatically during RL rather than manually created by prompting or SFT.”