
How to protect contrastive learning models against adversarial attacks

Contrastive learning (CL) is a machine learning technique that has gained popularity in the past few years because it reduces the need for annotated data, one of the main pain points of developing ML models.
But due to its peculiarities, contrastive learning presents security challenges that are different from those found in supervised machine learning. Machine learning and security researchers are worried about the effect of adversarial attacks on ML models trained through contrastive learning.
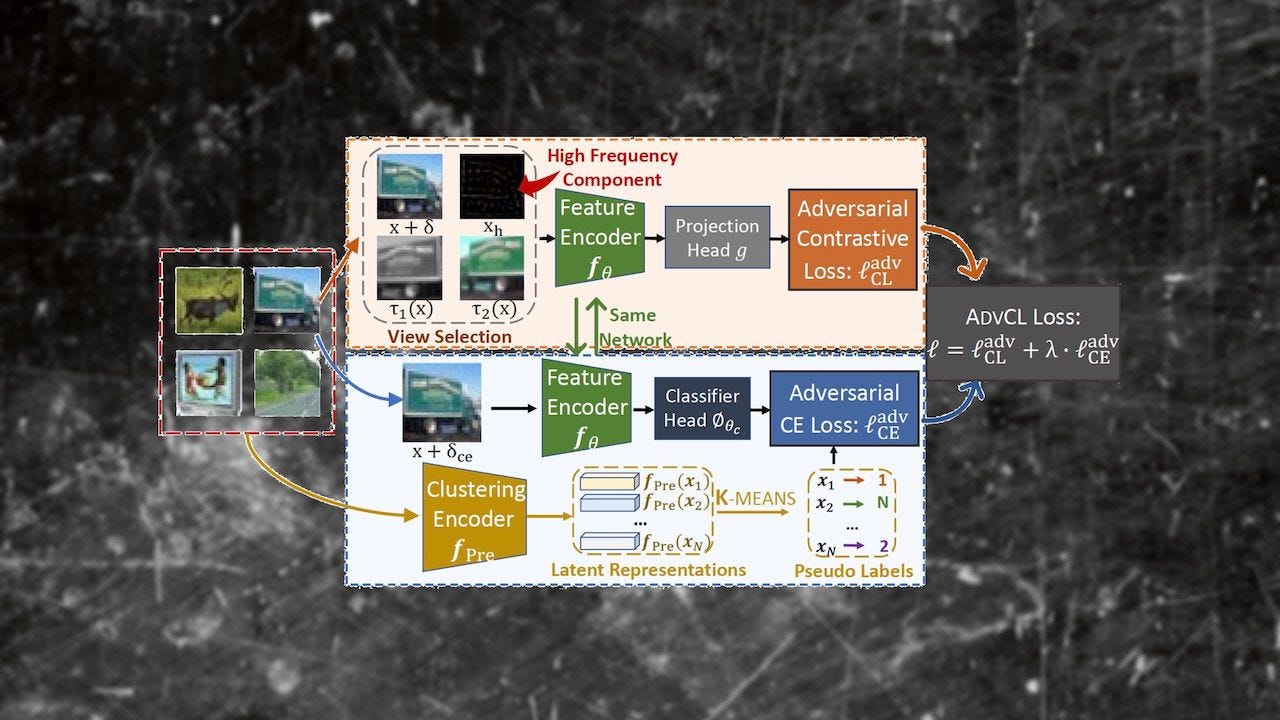
A new paper by researchers at the MIT-IBM Watson AI Lab sheds light on the sensitivities of contrastive machine learning to adversarial attacks. Accepted at NeurIPS 2021, the paper introduces a new technique that helps protect contrastive learning models against adversarial attacks while also preserving their accuracy.
Read the full article on TechTalks.
For more on machine learning security:
Computer vision and deep learning provide new ways to detect cyber threats
Machine learning adversarial attacks are a ticking time bomb
Create adversarial examples with this interactive JavaScript tool