


How to train LLMs for reasoning without RL or large labeled datasets
Stanford's "Think, Prune, Train" framework enables LLMs to enhance reasoning skills through self-generated data, leading to more efficient and smarter systems.


This article is part of our coverage of the latest in AI research.
The scarcity of high-quality training data remains one of the main hurdles to improving he reasoning abilities of large language models (LLMs).
A new study from Stanford University researchers explores an intriguing alternative: Can models improve their reasoning skills by learning from their own generated reasoning traces? They introduce "Think, Prune, Train" (TPT), a framework that allows models to iteratively refine their reasoning capabilities using carefully selected, self-generated data.
This approach could be a step towards creating smarter, more efficient AI without simply building ever-larger models and datasets.
The challenge of improving AI reasoning
Currently, two main strategies dominate efforts to enhance LLM reasoning after their initial training. One involves "supervised fine-tuning" (SFT), where models learn from curated datasets of problems and their step-by-step solutions. Another popular method is "distillation," where a smaller model learns by mimicking the outputs of a much larger, more capable "teacher" model.
Both approaches have limitations. SFT requires large, high-quality datasets of reasoning examples, which are often expensive and time-consuming to create. Distillation, on the other hand, depends entirely on having access to powerful, often proprietary, teacher models.
This raises a compelling question: Could models improve by recursively fine-tuning on data they generate themselves? Early attempts at this faced a significant hurdle known as "model collapse." When models were trained iteratively on their own unfiltered outputs, their performance often degraded over time. They could start hallucinating, forgetting previously learned knowledge, and producing lower-quality text, essentially entering a downward spiral.
A related, though distinct, risk in iterative training is "mode collapse." This happens when a model starts converging on a narrow set of high-probability outputs, becoming less diverse and exploratory in its responses. While prior work on model collapse focused on general text generation without a clear right or wrong answer, recursive fine-tuning on reasoning tasks, where correctness can be verified, introduces the possibility of mode collapse, where the model narrows down on very specific answers and loses the ability to explore alternative reasoning paths.
Think, Prune, Train (TPT)
The Stanford researchers behind TPT wanted to see if self-improvement was possible without the complexities often associated with other methods. While much prior work frames self-improvement as a reinforcement learning (RL) problem, TPT takes a more direct route.
It uses standard supervised fine-tuning (SFT), but with a crucial twist: the model is fine-tuned only on its own generated reasoning attempts that have been verified as correct. The researchers explored whether effective iterative refinement could be achieved purely through careful selection of this self-generated data.
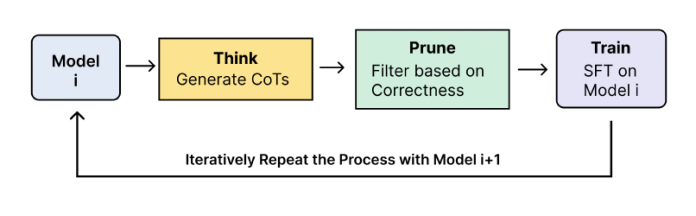
The Think, Prune, Train framework works like this:
Think: Prompt the current version of the model to generate step-by-step solutions (reasoning traces or "Chain-of-Thought") for a set of problems.
Prune: Filter the solutions, keeping only those that are demonstrably correct by checking against a known ground truth answer. This correctness-based pruning is key to avoiding the model collapse seen in earlier recursive training attempts.
Train: Fine-tune the model using SFT on the set of its own validated, correct reasoning traces.
This cycle is then repeated, with the newly improved model generating the data for the next round.
Crucially, unlike RL-based methods used in models like DeepSeek-R1 or the post-training of LLaMA 3.1, TPT focuses exclusively on this recursive, correctness-based SFT. It demonstrates that self-improvement is achievable without needing RL, learned reward functions, or external teacher models, relying instead on structured prompting and ground-truth validation.
To rigorously test if the improvements came from genuine self-refinement rather than just exposure to more data, the researchers designed their experiments carefully. In each TPT round, they kept the training dataset size constant, using only a single, unique correct solution per problem.
Furthermore, instead of accumulating data across rounds, they replaced the training set with newly generated solutions from the latest model version. This ensured that any performance gains were truly due to the iterative refinement process.
As the paper notes, “Our findings suggest that with strict data constraints, iterative fine-tuning can lead to meaningful gains, demonstrating that model improvement is not solely a function of dataset expansion.”
Making smaller models punch above their weight
The researchers tested TPT on instruction-tuned versions of Google's Gemma models (gemma2-2b-it, gemma2-9b-it) and Meta's Llama models (Llama-3.1-1B-Instruct, Llama-3.1-70B-Instruct), evaluating them primarily on the GSM8K math word problem benchmark and the CodeContests programming challenge dataset.
The results were striking. Using the TPT process, relatively small models achieved reasoning performance comparable to, or even exceeding, much larger base models. For instance, on GSM8K, the Gemma2-2B model's accuracy (Pass@1, meaning correct on the first try) jumped from 41.9% to 57.6%. Gemma2-9B surpassed the baseline performance of the much larger LLaMA-3.1-70B-Instruct. In turn, LLaMA-3.1-70B with TPT boosted its Pass@1 score from 78.6% to 91.5%, outperforming even reported scores for GPT-4o on this benchmark at the time.
Interestingly, the rate of improvement varied. The smaller Gemma-2-2B model needed four TPT rounds to reach its peak, while the mid-sized Gemma-2-9B improved faster over three rounds. The large LLaMA-70B model saw dramatic gains after just one round, suggesting that larger models might integrate self-generated reasoning lessons more rapidly.

The researchers also investigated the possibility of mode collapse. While the models' accuracy on the first attempt (Pass@1) consistently increased, their ability to generate diverse correct answers within multiple attempts (measured by Pass@20 or Pass@50) tended to plateau after the initial round. This suggests the TPT process does indeed guide the model towards prioritizing high-confidence, correct solutions over exploring diverse reasoning paths. However, the researchers argue this isn't necessarily detrimental for tasks like math and programming, where correctness and efficiency are often paramount. By focusing the model on validated reasoning, TPT might even help reduce hallucinations and improve reliability in accuracy-sensitive applications.
The Think, Prune, Train framework offers a compelling argument that LLMs can teach themselves to become better reasoners. As the researchers write, "structured reasoning prompting, correctness-based pruning, and supervised fine-tuning on validated solutions enable scalable self-improvement without external supervision, highlighting the potential of simplistic frameworks to unlock further advances in LLM reasoning and accuracy.”
is validation phase human validated or LLM based?