
Hybrid model-based and model-free RL achieves superior performance

Reinforcement learning is one of the fascinating fields of computer science, and it has proven its efficiency in solving some of the toughest challenges of artificial intelligence and robotics. Some scientists believe that reinforcement learning will play a key role in cracking the enigma of human-level artificial intelligence.
But many hurdles stand between current reinforcement learning systems and a possible path toward more general and robust forms of AI. Many RL systems struggle with long-term planning, training-sample efficiency, transferring knowledge to new tasks, dealing with the inconsistencies of input signals and rewards, and other challenges that occur in real-world applications. There are dozens of reinforcement learning algorithms—and more recently deep RL—each of which addresses some of these challenges while struggling with others.
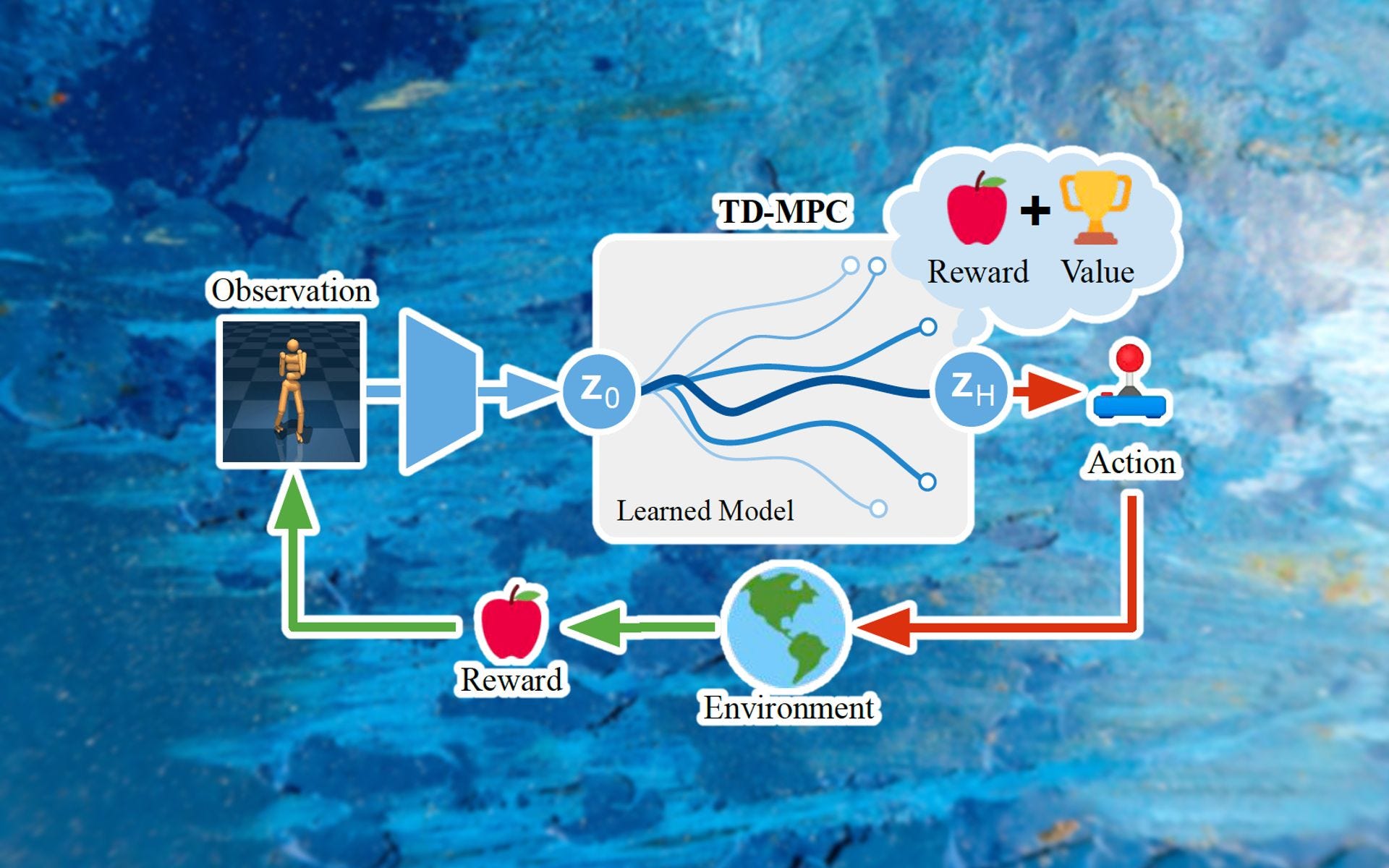
A new reinforcement learning technique developed by researchers at the University of California, San Diego, brings together two major branches of RL to create more efficient and robust agents. Dubbed Temporal Difference Model Predictive Control (TD-MPC), the new technique combines the strengths of model-based and model-free RL to match and outperform state-of-the-art algorithms in challenging tasks.
Read the full article on TechTalks.
For more on AI research: