
If you want to scale LLMs gradually, look to Tokenformer
Tokenformer uses the attention mechanism exclusively to create a transformer architecture that can be scaled without training from scratch.


There are so many ways you can fiddle with the Transformer architecture to make it more efficient. A recent research paper by Google, Max Planck Institute, and Peking University introduces Tokenformer, a variant of the Transformer model that makes it possible to gradually scale models without the need to train them from scratch. This is important because foundation models often come in families of various sizes, and being able to build them on top of each other could save a lot of resources.
Design limitations of Transformers
Transformer blocks usually contain two types of computations. The first part uses the attention mechanism to compute the interaction between tokens. The second part uses feed-forward networks (FFN) to perform further transformations on the attention values.
While this architecture has proven very effective, it has scalability limitations. Increasing a model’s size requires making important changes to the architecture, often requiring retraining the model from scratch. This can become especially cumbersome as you scale models to billions and hundreds of billions of parameters.
Ideally, you should be able to build larger models on top of smaller ones and reuse their existing weights to reduce training costs.
Tokenformer
Tokenformer is a novel architecture that makes it possible to incrementally scale models without the need to train them from scratch. The main Tokenformer introduces is removing the FFN layers and using the attention mechanism for computing token interactions and model parameters.

Tokenformer replaces the classic Transformer block with the “Parameter attention” (Pattention) layer, which includes a set of “trainable tokens” that function as the model parameters that were previously included in the separate FFN layers.
By using the Pattention layer, Tokenformer decouples the model parameters from the input and output dimensions, making it possible to change the number of parameters without breaking the existing architecture. Effectively, this means you can gradually increase the size of the model and the number of parameters while preserving the existing knowledge that the model has learned.

“Pattention layer is designed to process a flexible number of parameters independently of the input and output channel dimensions used in feature projection,” the researchers write. “This allows network parameters to be expanded seamlessly along the parameter token axis, enabling the effective reuse of pre-trained weights and offering a naturally incremental manner for model scaling.”
Tokenformer in action
The researchers tested Tokenformer by scaling GPT-style language models from 124 million to 1.4 billion. The scaling procedure started with an initial source model trained from scratch on 300 billion tokens. For each scaling iteration, the smaller Tokenformer model was used to initialize the weights of the larger one.
For example, they trained the 124M parameter model from scratch. In the next stage, they used the model to partially initialize the 345M parameter model and trained the latter on a smaller corpus of 15-60 billion tokens. In contrast, classic Transformers need to be trained from scratch with the full corpus.
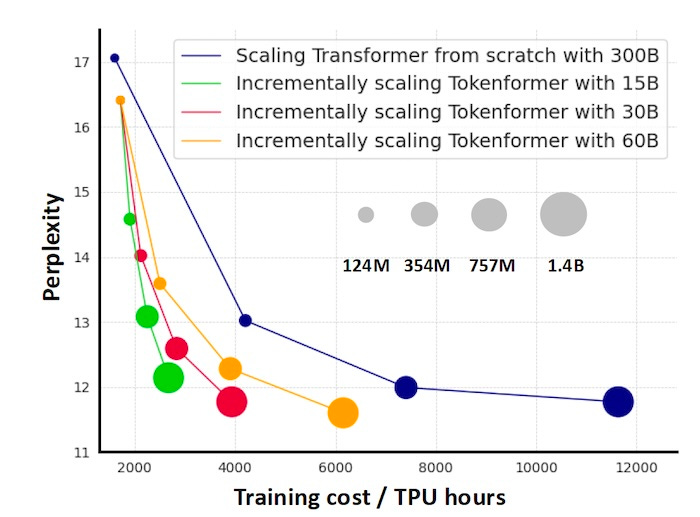
The researchers were able to gradually scale Tokenformers from 124M to 1.4B parameters with only 10% of the computational budget required to train the same family of Transformers.
“Our progressive scaling methodology employing Tokenformer achieves performance comparable to that of a Transformer model trained from scratch, while substantially reducing the training budget,” the researchers write.
The code for Tokenformer is available on GitHub.
The Transformer and the attention mechanism have turned out to be very interesting architectures. Last week, I explored another paper that showed how you can remove a lot of the attention layers from Transformers while preserving their accuracy. This is a very flexible architecture that can be optimized in various ways, depending on the needs of the environment and the application.