
Improving LLM reasoning with step-wise reinforcement learning
SWiRL trains models to interleave reasoning, tool-use, and answer generation, making it useful for agentic applications.


Step-Wise Reinforcement Learning (SWiRL), a new technique developed by DeepMind and Stanford University, improves the ability of LLMs in multi-step reasoning with tool use, proving to be useful for real-world applications that require interacting with complex environments.
Traditional RL methods, such as Reinforcement Learning from Human Feedback (RLHF) and RL from AI Feedback (RLAIF), optimize models for single-step reasoning tasks. This makes them inefficient for tasks that require the model to reassess its current reasoning path midway and retrieve additional information and help from external sources and tools.
SWiRL uses synthetic data generation and a specialized RL approach to teach the LLMs to “decompose complex problems into a sequence of more manageable subtasks, when to call the tool, how to formulate a call to the tool, when to use the results of these queries to answer the question, and how to effectively synthesize its findings.”
SWiRL works in two stages: data generation and step-wise RL training.
In the first stage, an LLM is given access to a relevant tool, like a search engine or a calculator and is prompted to generate a "trajectory” that includes chain-of-thought (CoT) reasoning, tool calling, or producing the final answer. If the model opts to use a tool, the query is extracted and executed (e.g., a search query of calculator call) and the result in inserted into the model’s context. The trajectory generation continues until the model produces the final answer.
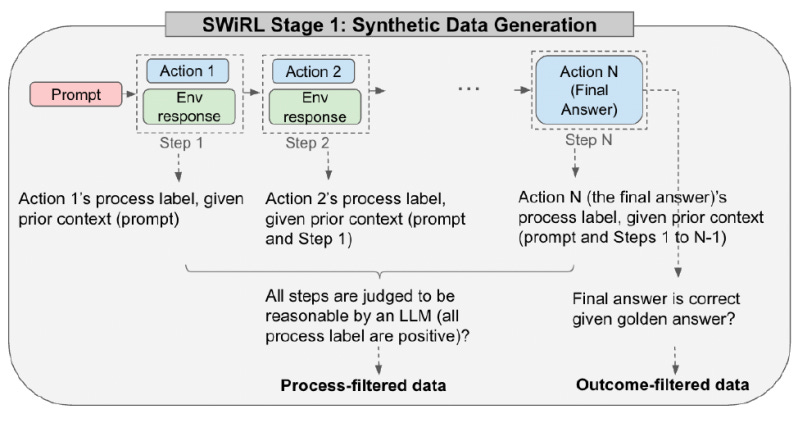
To create the training dataset, the researchers first generated tens of thousands of trajectories from HotPotQA and GSM8K benchmarks. They then broke down each trajectory into sub-trajectories that begin from the prompt, gradually adding each step until the answer is given.
Unlike standard approaches that rely heavily on “golden labels,” the SWiRL team used “process-filtering,” which means the training data included trajectories where each reasoning step or tool call was logical given the previous context, even if the final answer was wrong.
“In fact, we achieve our best results by including process-filtered data, regardless of the correctness of the outcome,” the researchers write.
In the second stage of SWiRL, the researchers used RL to train an LLM on the generated trajectories. The model is given the sub-trajectories and optimized to predict the next appropriate action based on the preceding context.

“Our granular, step-by-step finetuning paradigm enables the model to learn both local decision-making (next-step prediction) and global trajectory optimization (final response generation) while being guided by immediate feedback on the soundness of each prediction,” the researchers write.
During inference, the model works in the same step-by-step process, receiving a prompt, choosing an action (reasoning, tool use, answer), and repeating until it reaches the answer of exhausts a preset number of steps.

In the experiments the team ran, models trained SWiRL outperformed baseline models from 11% to over 21% on datasets like GSM8K, HotPotQA, MuSiQue, and BeerQA.
The experiments confirmed that training SWiRL on process-filtered data yielded the best results, suggesting that SWiRL learns the underlying reasoning process instead of memorizing paths to correct answers.
Techniques such as SWiRL can be useful in training the next generation of reasoning models for agentic applications that interact with multiple tools and environments.
