
Inside FlashOptim, the new trick that cuts LLM training memory by 50 percent
Training large language models usually requires a cluster of GPUs. FlashOptim changes the math, enabling full-parameter training on fewer accelerators.


Training large language models is an expensive endeavor, largely due to the massive accelerator memory required for each parameter during the training process. To reduce the costs, researchers at Databricks introduced FlashOptim, a suite of memory-optimization techniques designed for common deep learning optimizers. FlashOptim acts as a drop-in replacement that slashes per-parameter memory consumption by more than 50 percent. It achieves this without sacrificing training throughput or model quality. According to the research team, this efficiency “enables practitioners and researchers with limited hardware to train larger models than previously feasible.”
The memory bottleneck of LLM training
Before exploring how FlashOptim works, it helps to understand why training a neural network demands so much hardware. During training, every model parameter brings a heavy baggage of additional variables that must be stored in the GPU’s memory. First, you have the parameters themselves, which are the actual neural network weights being learned.
Developers frequently rely on mixed-precision training to speed up calculations, executing forward and backward passes using 16-bit floating-point numbers. However, standard practice requires keeping a high-precision 32-bit master weight in memory to prevent errors when accumulating very small gradient updates. Second, the training system calculates a gradient for every single parameter during the backward pass of backpropagation. Gradients dictate the direction and magnitude of the required update, and they typically occupy another 4 bytes of memory per parameter since they are stored as 32-bit floats.
Third, modern optimizers like Adam or AdamW track historical statistics to smooth out the learning trajectory. Adam maintains two specific state variables for every parameter: momentum, which is a running average of past gradients, and variance, a running average of squared gradients. Since both states are usually maintained in 32-bit precision, the optimizer alone eats up 8 bytes of memory per parameter. Finally, the model calculates intermediate outputs, known as “activations,” during the forward pass. The system must temporarily hold these activations in memory because the backward pass requires them to compute the gradients. Unlike the weights, gradients, and optimizer states, which scale strictly with the size of the model, activation memory scales based on your batch size (the number of training examples you feed the model before updating the weights).
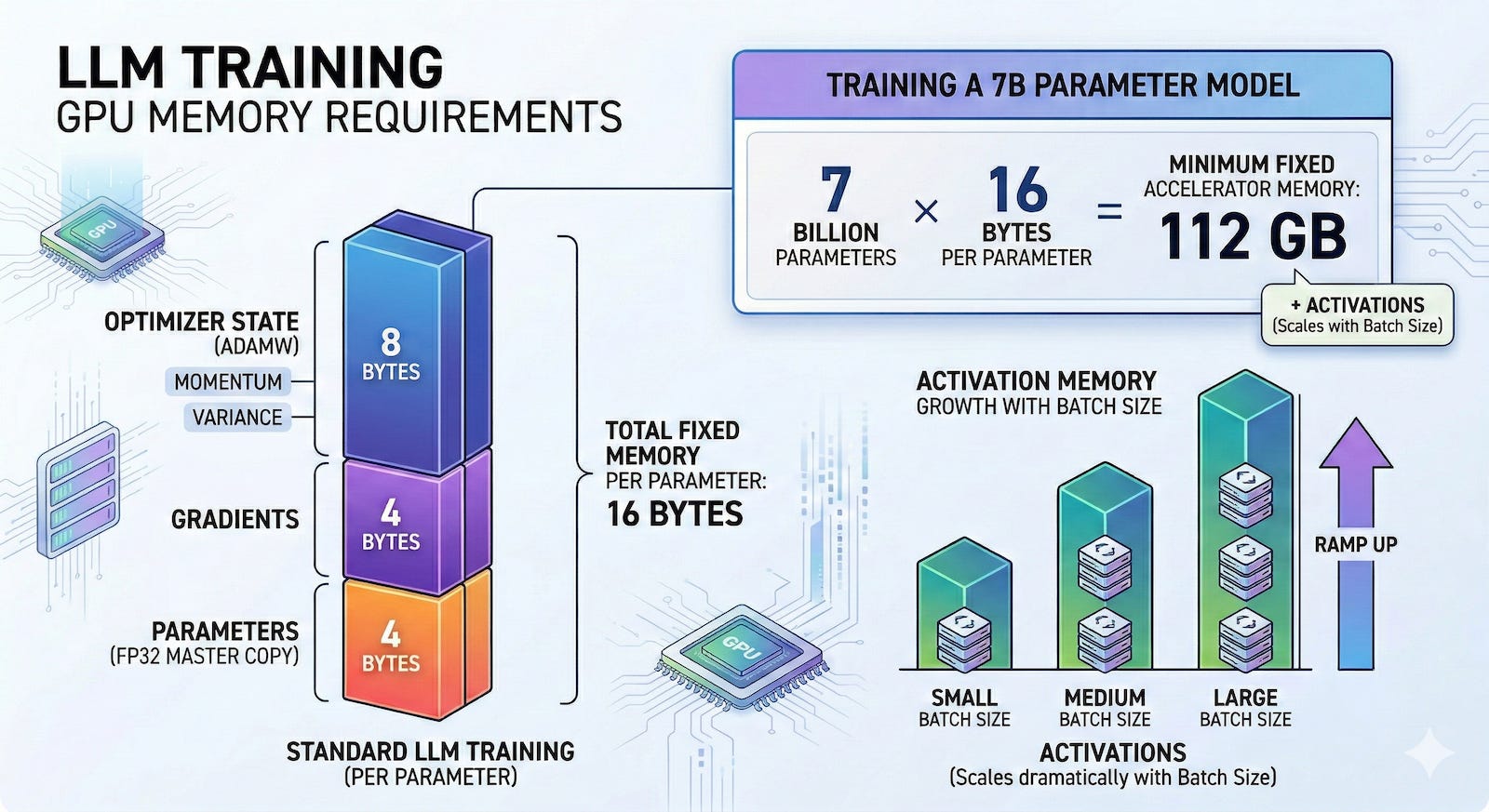
When you combine the parameters, gradients, and optimizer states, a standard training setup using Adam demands roughly 16 bytes of memory for every single parameter. This means if a developer wants to train a 7-billion parameter language model, they must provision at least 112 gigabytes of accelerator memory purely to hold the model and its optimization variables. That calculation does not even include the extra memory needed to process the data batches.
Current approaches fall short
The deep learning community has developed several workarounds to deal with these hardware constraints, but each comes with significant trade-offs. One common method is distributed training with tensor sharding. Frameworks PyTorch’s Fully Sharded Data Parallel partition the memory load across a cluster of multiple GPUs. While this is the standard operating procedure inside well-resourced tech organizations, it strictly requires access to a fleet of accelerators. For independent developers, researchers, or smaller teams working with a single GPU, this approach is physically impossible to implement.
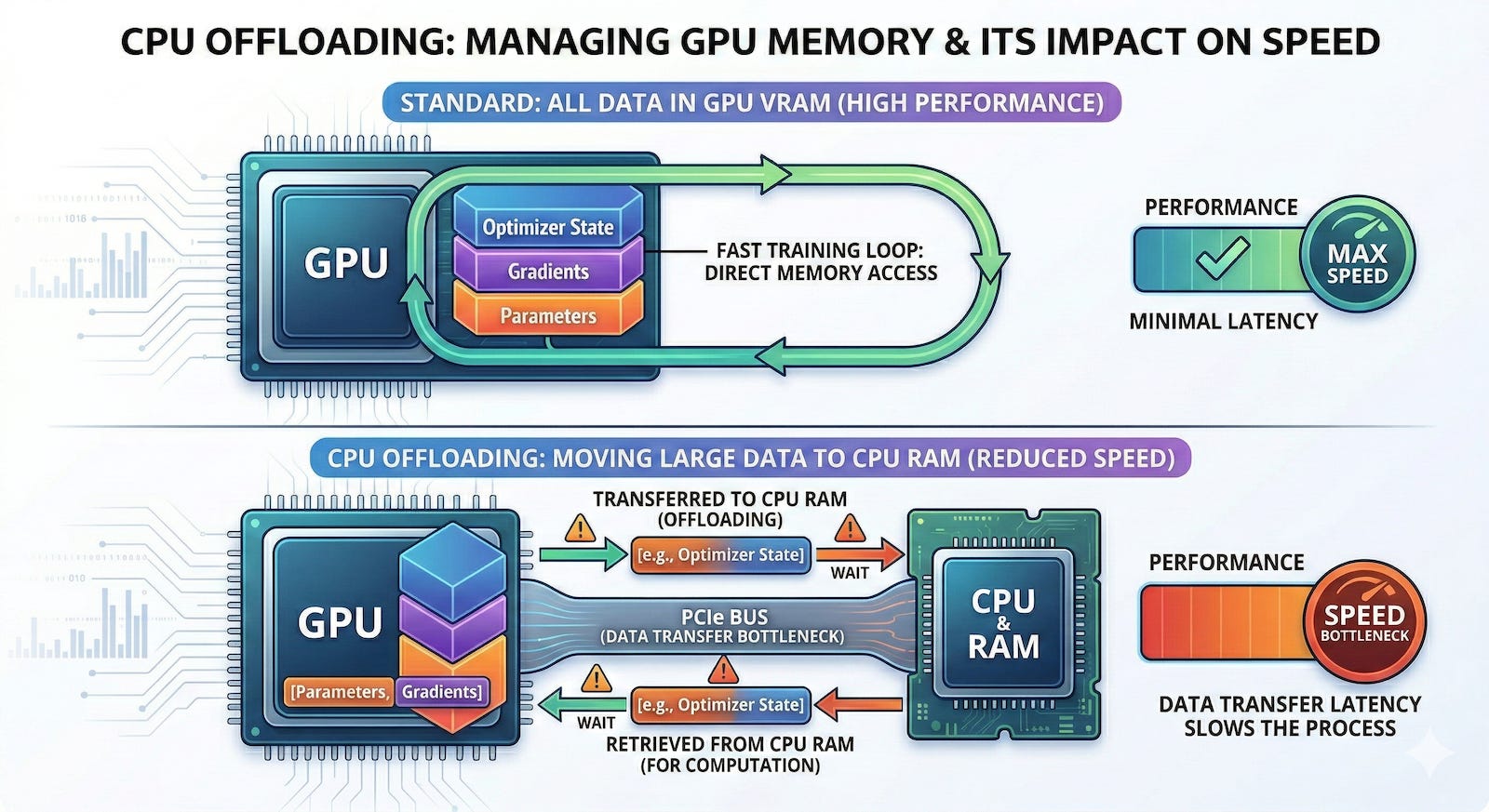
Another alternative is CPU offloading. GPU memory is expensive and scarce, but host system memory is relatively cheap and abundant. Offloading techniques temporarily move certain memory-hungry tensors out of the GPU and into the host machine’s RAM, pulling them back only when the accelerator needs them for a specific calculation. The downside is that moving gigabytes of data back and forth over a PCIe bus creates a massive communication bottleneck. This shuffling introduces added overhead and complexity that ultimately slows down the training loop.
A third popular workaround involves parameter-efficient methods, such as low-rank adaptation (LoRA). Instead of updating every single parameter in a massive model, these techniques freeze the vast majority of the original weights. The system then only calculates gradients and optimizer states for a tiny subset of the original weights, or for a small set of new auxiliary weights injected into the architecture. The catch is that intentionally ignoring most of the network fundamentally alters the training dynamics. Parameter-efficient fine-tuning is an approximation that does not follow the exact same learning trajectory as full-parameter fine-tuning, which can limit performance on complex tasks.
Redesigning memory efficiency with FlashOptim
The Databricks researchers took a different route, building FlashOptim as a set of techniques to compress parameter-associated memory directly within common deep learning optimizers. FlashOptim achieves this through improved float splitting, companded optimizer state quantization, and fused optimized kernels.
Developers typically keep a 32-bit master weight alongside a downcasted 16-bit version used for the actual forward and backward passes. Keeping both in memory is highly redundant because the 16-bit weight stores little information that isn’t already in the master weight. Previous attempts to split these weights stored the 16-bit base weight along with a 16-bit error correction, but this method wasted valuable data bits trying to cover the massive range of standard floating-point numbers.
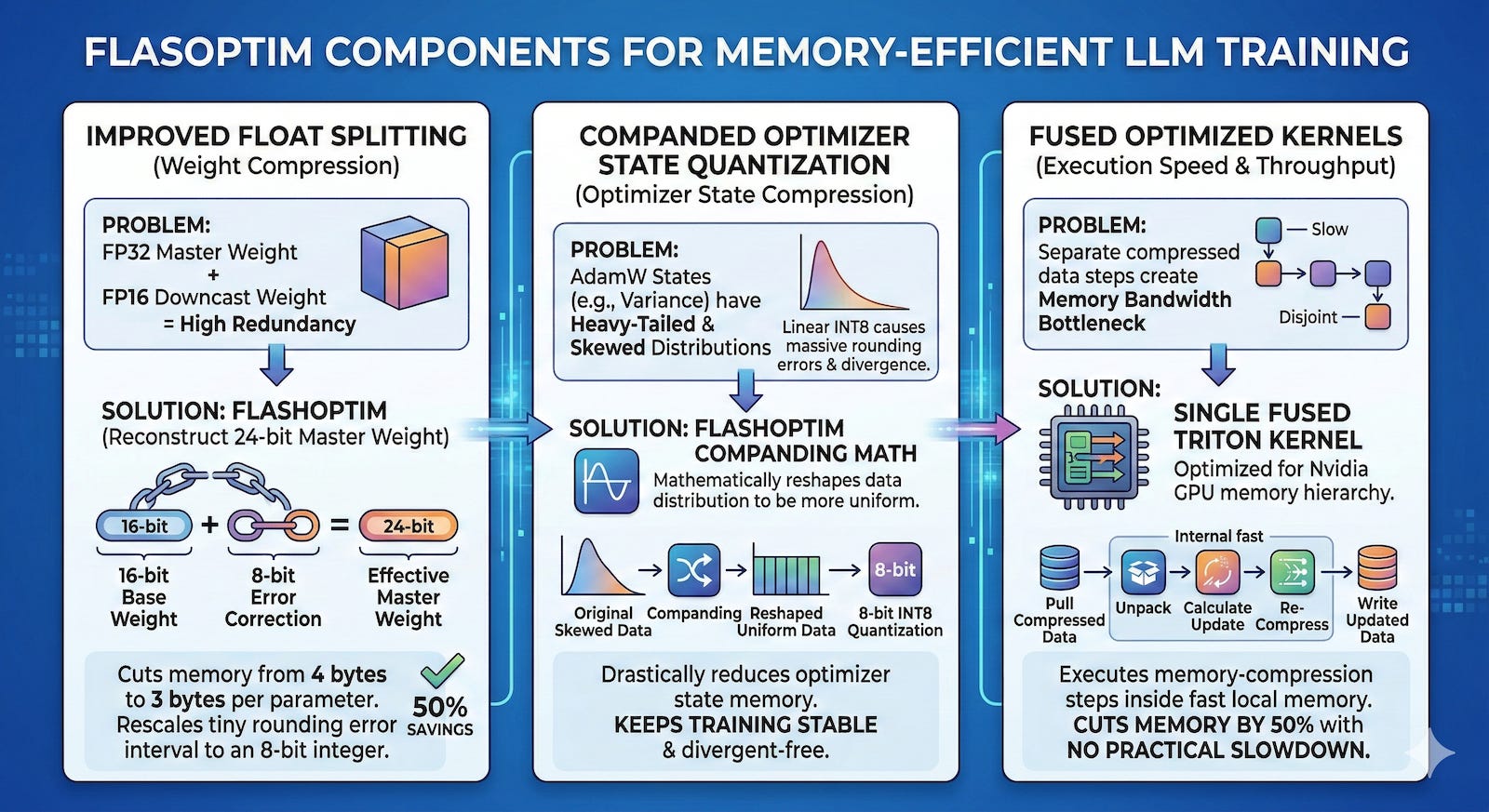
The Databricks team made a clever observation: under round-to-nearest rules, the rounding error between a 32-bit master weight and its 16-bit downcast version must fall within a microscopic, predictable interval. Instead of storing a wide-ranging float, FlashOptim’s “improved float splitting” technique rescales this tiny error interval and maps it to the nearest 8-bit integer. By combining the 16-bit base weight with this 8-bit error correction, FlashOptim successfully reconstructs a 24-bit master weight. This innovation cuts the total weight memory requirement from 4 bytes down to 3 bytes per parameter, with virtually no loss in precision.
The second major breakthrough is “companded optimizer state quantization.” Traditional attempts to shrink the optimizer state simply group the numbers and squeeze them into 8-bit integers. This linear quantization implicitly assumes that optimizer values are distributed evenly across the spectrum. However, the measurements showed that optimizer state distributions severely violate this assumption. Variance, for instance, accumulates squared gradients, producing heavily skewed, heavy-tailed distributions. Forcing these highly skewed numbers into evenly spaced 8-bit bins creates massive quantization errors. Before converting the numbers, FlashOptim applies a mathematical trick called a companding function, which compresses extreme values and reshapes the data distribution so it is more uniform. After this companding step, the values fit perfectly into 8-bit bins with significantly reduced error. This reduces the optimizer state from 8 bytes per parameter down to just 2 bytes, plus a tiny fraction of a byte required for group scaling factors.
FlashOptim packages these techniques into fused optimized kernels. Splitting weights, dequantizing states, performing math updates, and re-compressing everything requires moving a lot of data back and forth. Implementing this naively would create a massive memory bandwidth bottleneck. FlashOptim solves this by implementing the entire optimizer step as a single fused Triton kernel designed for Nvidia hardware. The GPU pulls the compressed data into its fast local memory, unpacks it, calculates the update, compresses the results, and writes it all out in one seamless operation. This allows FlashOptim to cut memory consumption without causing any practical slowdown during training.
FlashOptim in action
To prove the framework’s real-world viability, the researchers tested FlashOptim on several standard vision and language benchmarks. This included pretraining a GPT-2 architecture and running supervised fine-tuning on the massive Llama-3.1-8B model. Across the stochastic gradient descent (SGD), AdamW, and Lion optimizers, models trained with FlashOptim matched the loss trajectories, convergence rates, and final validation accuracies of their standard, memory-hungry counterparts.
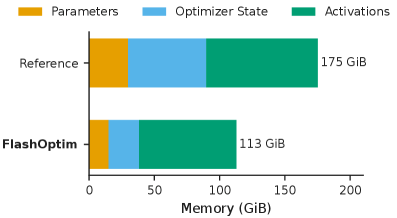
During the Llama-3.1-8B fine-tuning test, peak GPU memory dropped from 175 gigabytes to 113 gigabytes, representing a 36 percent overall reduction. Looking closer at the breakdown, the optimizer memory shrank by 61 percent, and the parameter memory dropped by 50 percent. Because FlashOptim executes its mathematical operations inside highly efficient fused kernels, these compressions don’t slow down the training process. In fact, the optimizer step time during the Llama-3.1 test actually dropped slightly from 12.5 milliseconds to 11.5 milliseconds.
For developers, FlashOptim’s greatest value might be its simplicity. It provides drop-in replacements for common optimizers, meaning developers do not need to rewrite their training loops, alter optimization semantics, or invent new tuning strategies. The researchers plan to release FlashOptim as an open-source PyTorch library on GitHub.
Great write up, thanks! A throughput comparison alongside the memory comparison (assuming the new pack unpack operations have some impact) would have been very nice here. However i do understand that the memory is much more of a fundamental limit than how fast it runs.
nice! i agree with the simplicity bonus. i really like this