
Inside URM, the architecture beating standard Transformers on reasoning tasks
The key to solving complex reasoning isn't stacking more transformer layers, but refining the "thought process" through efficient recurrent loops.


Researchers at Ubiquant have proposed a new deep learning architecture that improves the ability of AI models to solve complex reasoning tasks. Their architecture, the Universal Reasoning Model (URM), refines the Universal Transformer (UT) framework used by other research teams to tackle difficult benchmarks such as ARC-AGI and Sudoku.
While recent models like the Hierarchical Reasoning Model (HRM) and Tiny Recursive Model (TRM) have highlighted the potential of recurrent architectures, the Ubiquant team identified key areas where these models could be optimized. Their resulting approach substantially improves reasoning performance compared to these existing small reasoning models, achieving best-in-class results on reasoning benchmarks.
The case for universal transformers
To understand the URM, it is necessary to first look at the Universal Transformer (UT) and how it differs from the standard architecture used in most large language models (LLMs). A standard transformer model processes data by passing it through a stack of distinct layers, where each layer has its own unique set of parameters.
In contrast, a UT applies a single layer (often called a transition block) repeatedly in a loop to refine the token representations. This weight-tying mechanism allows the model to perform iterative reasoning without increasing the number of parameters, making it theoretically more expressive for tasks that require depth-intensive thinking.
Recent iterations of this concept, such as HRM and TRM, have shown that small UT-based models can outperform much larger standard transformers on reasoning tasks.
")
However, the authors of the URM paper argue that the specific source of these performance gains has been misunderstood. While prior studies attributed success to elaborate architectural designs, the Ubiquant researchers found that the improvements primarily arise from the “recurrent inductive bias” intrinsic to the Universal Transformer. In other words, the benefit comes from the model’s ability to reuse the exact same parameters to refine a thought process.
Furthermore, their analysis revealed that “nonlinear depth-wise computation” plays a much larger role than previously acknowledged. Specifically, the Feed-Forward Network (or MLP) rather than the attention mechanism (which is the key component of the transformer block) constitutes the primary source of the expressive nonlinearity required for complex reasoning.
Enhancing the reasoning loop
Building on these insights, the URM introduces two key innovations to the UT framework: the ConvSwiGLU module and Truncated Backpropagation Through Loops (TBPTL).
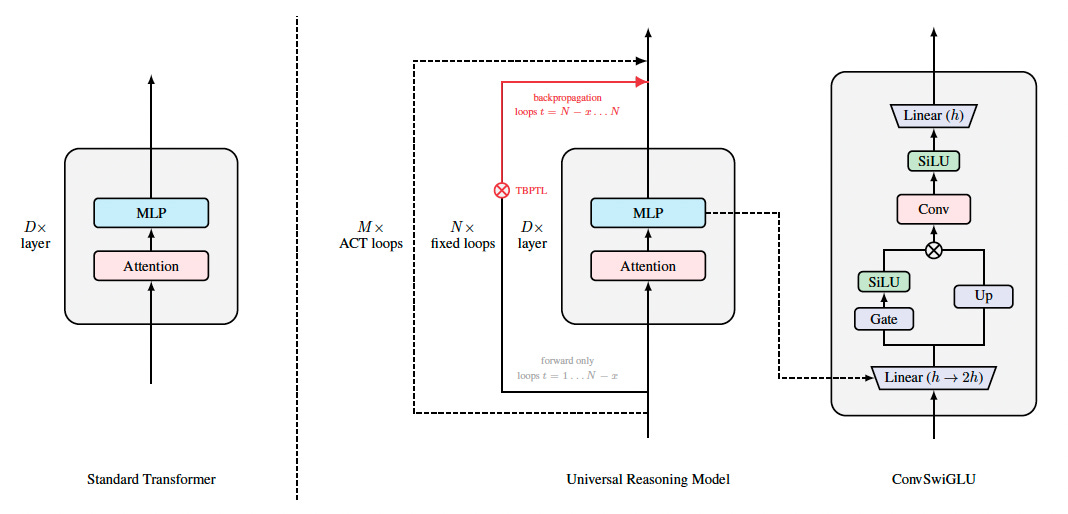
The first innovation addresses the limitations of the standard SwiGLU activation function used in the MLP blocks of modern transformers. While SwiGLU provides necessary nonlinearity, it is a point-wise operation that processes every token independently, preventing information from mixing between different tokens in that specific layer. The researchers augmented this by inserting a depthwise short convolution inside the MLP block. This ConvSwiGLU mechanism forces local contextual interactions, allowing the model to mix information between channels in the token space without significantly increasing computational complexity.
The second innovation, Truncated Backpropagation Through Loops, addresses the training instability inherent in recurrent models. Because the URM relies on looping the same layer, deep reasoning requires many iterations. However, calculating gradients across a long chain of loops can lead to noise accumulation and optimization issues. To solve this, the researchers partitioned the rollout into “forward-only” and “trainable” segments.
For a setup with 8 inner loops, they found the optimal balance was to run the first two loops as forward-only, calculating gradients only for the final six loops. This technique stabilizes training by ignoring the noisy gradients from the earliest stages of the reasoning process, allowing the model to focus on refining the later stages.
URM in action
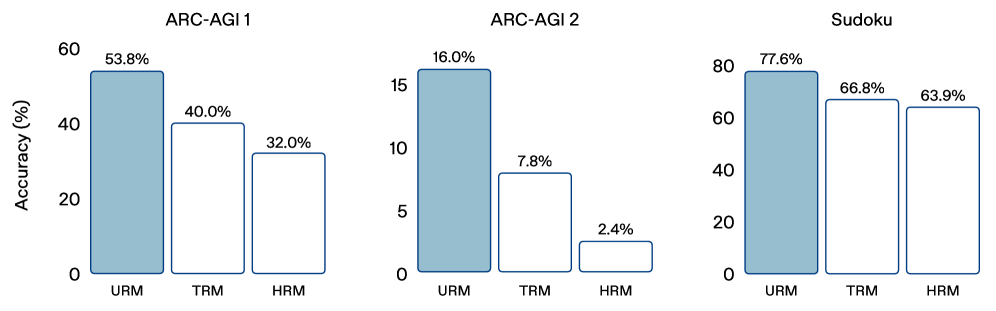
The combination of these architectural changes resulted in substantial performance gains over prior UT-based approaches. On the ARC-AGI 1 benchmark, URM achieved a 53.8% on a single run (pass@1), significantly outperforming TRM (40.0%) and HRM (34.4%). URM took an even bigger lead on ARC-AGI 2, where it obtained 16.0% pass@1, nearly tripling the score of HRM and more than doubling TRM. It had a similar advantage on the Sudoku benchmark, reaching 77.6% accuracy.
Beyond raw accuracy, the results highlight the efficiency of the recurrent approach. The researchers showed that a UT with only four times the parameters of a base transformer block could achieve a pass@1 score of 40.0, dramatically outperforming a vanilla transformer with 32 blocks.
The researchers also note that “simply scaling depth or width in vanilla Transformers yields diminishing returns and can even lead to performance degradation, highlighting a fundamental inefficiency in how parameters are used to support multi-step reasoning.”
The findings indicate that iterative computation is often more beneficial than simply adding more independent layers. As the authors explain, “In standard Transformers, additional FLOPs are often spent on redundant refinement in higher layers, whereas recurrent computation converts the same budget into increased effective depth.”
The researchers have released the code for URM on GitHub.
It is worth noting that URM and UTs are still far behind frontier models in reasoning benchmarks such as ARC-AGI. Poetiq recently developed a refinement technique that achieves 54% on ARC-AGI-2, far above URM. The Universal Transformer models are also trained specifically for ARC-AGI-type problems (even if they are not overfit to those specific datasets), which doesn’t make them useful for general applications that frontier LLMs tackle. But they are novel experiments that show how new architectures and approaches can tackle complex problems at a fraction of the compute and memory budget previously required. It will be interesting to see the new research directions and applications that UT models lead to.