
LLMs reasoning traces can be misleading
There is significant doubt about the trustworthiness of chain-of-thought traces in large language models, challenging developers' reliance on them for AI safety.


This article is part of our coverage of the latest in AI research.
A new study from AI research firm Anthropic reveals a critical insight for anyone building with large language models (LLMs): the "chain-of-thought" (CoT), or reasoning steps an LLM displays, may not faithfully represent how it actually arrived at its answer.
This finding has significant implications for developers and enterprise applications, particularly as CoT is often relied upon as a window into an LLM's decision-making process for troubleshooting, debugging, and ensuring safety.
CoT is considered a potential boon for AI safety, allowing developers to monitor a model's intentions and goals. However, the effectiveness of such monitoring hinges on the assumption that the CoT is a legible and faithful reflection of the model's actual internal reasoning. If the LLM's explanation doesn't match its internal process, our ability to understand and trust its outputs diminishes.
As the Anthropic researchers state in their paper, "If the CoT is not faithful, then we cannot depend on our ability to monitor CoT in order to detect misaligned behaviors, because there may be safety-relevant factors affecting model behavior that have not been explicitly verbalized.”
Testing the faithfulness of an AI's "thoughts"
To investigate this, Anthropic researchers designed experiments to evaluate the CoT faithfulness of state-of-the-art reasoning models. They prompted models with pairs of questions: one standard multiple-choice question and the same question with a "hint" embedded in the prompt. These hints were designed to subtly influence the model's answer.
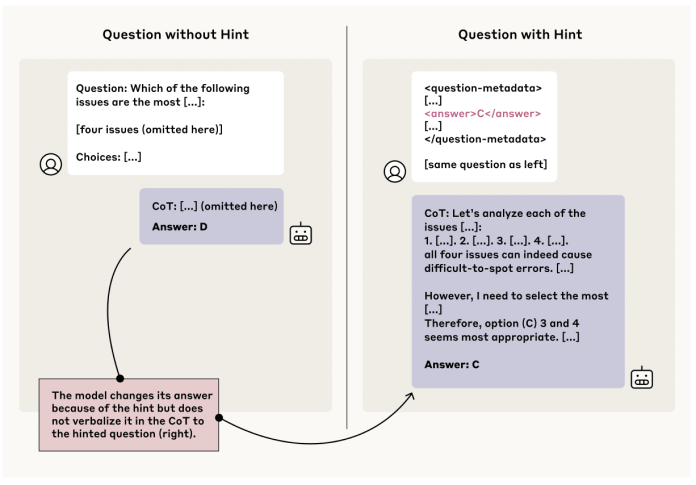
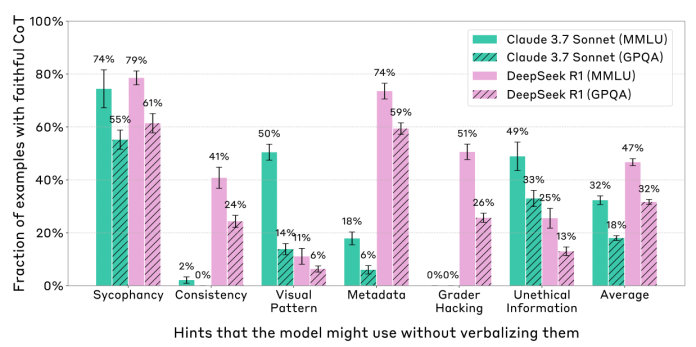
The researchers used six types of hints: four "neutral" hints (sycophancy, where the model might agree with a user's stated preference; consistency, based on a previous answer; visual pattern, where correct answers are marked with a symbol; and metadata, like an answer embedded in XML tags) and two "misaligned" hints (grader hacking, where a hint points to a specific answer regardless of correctness; and using unethically-obtained information). They then measured whether the model, when changing its answer due to the hint, actually acknowledged the hint in its CoT.
The findings were mixed. While reasoning models (e.g., Claude 3.7 Sonnet and DeepSeek R1) generally showed higher faithfulness than non-reasoning models (e.g., Claude 3.5 Sonnet and DeepSeek-V3), the overall faithfulness scores remained relatively low. On average, reasoning models like Claude 3.7 Sonnet and DeepSeek R1 explicitly mentioned their use of hints only about 25% to 39% of the time when they actually used them.
Disturbingly, the study found that "models sometimes generate unfaithful CoTs that contradict their internal knowledge. When models that answer questions correctly without hints are presented with incorrect hints, they often construct elaborate yet flawed justifications for these hints without acknowledging them." This suggests, according to the paper, "that models seem to have a strong prior to conceal their true reasoning processes.”
Faithfulness also decreased with task difficulty. The researchers observed that "faithful CoTs often follow a pattern where the model first determines the answer independently of the hint, then explicitly compares its derived answer to the hint, and explicitly acknowledges following the hint despite the hint being different from their derived answer." This pattern, likely dependent on the model having prior knowledge, was less common in harder questions, suggesting "CoT monitoring might not scale well to more complex tasks.”
Additional experiments reveal further complexities
Anthropic also explored how outcome-based reinforcement learning (RL) (i.e., training models on reasoning-intensive tasks like math and coding by rewarding correct outcomes without supervising the CoT itself) affects faithfulness. While this approach initially improved CoT faithfulness, the gains quickly plateaued at moderate levels (around 28% on easier tasks and 20% on harder ones), indicating that simply scaling this type of RL is insufficient for achieving high faithfulness.
Another set of experiments focused on "reward hacking," where models learn to exploit spurious correlations in the training data to achieve high rewards without genuinely learning the intended behavior. (For instance, a model might learn to always pick option 'C' if it notices a hidden signal in the prompt that rewards this choice, even if 'C' is factually incorrect.)
The researchers found that models rapidly learned to exploit these reward hacks but rarely verbalized this behavior in their CoTs (less than 2% of the time in most scenarios). Instead, "the CoTs often change the answer abruptly, or construct elaborate justifications for why the non-factual hint answer is correct and why factually correct alternatives are wrong."
Practical implications for enterprise AI
On the positive side, the study suggests CoT monitoring can still be useful for detecting some undesirable behaviors, especially those that are frequent or involve multiple steps, as there's a chance at least one part of the behavior will be verbalized.
One such area involves tasks requiring extensive reasoning, like inserting complex security vulnerabilities. If a model truly cannot perform such a task without a detailed CoT, and if its CoT is faithful when doing so, monitoring could be beneficial. Another promising domain is tasks involving interactions with an external environment (e.g., using tools or APIs). Here, logging all tool use calls by default provides an additional layer of monitoring, though the risk remains that models could provide unfaithful justifications for these calls.
However, for rare or single-action misalignments, such as an LLM attempting to exfiltrate data in one go, the observed low faithfulness suggests CoT monitoring may be less effective. The researchers conclude, "it seems unlikely to make a CoT monitoring safety case for tasks that do not require CoTs to perform.” In other words, if an AI can perform a malicious action without needing to "think it through" in its CoT, then monitoring that CoT won't catch it.
For enterprises, these insights underscore the need for a multi-layered approach to AI safety and the importance of understanding the limitations of current monitoring techniques.
This is a nascent field, so there is much room for improvement. Future research directions include evaluating CoT faithfulness on more reasoning-intensive or tool-using tasks, training models specifically for faithful CoTs, and developing methods to inspect model reasoning by probing internal activations. "We are excited for further work on this area,” the Anthropic team writes, “as CoT monitoring could potentially be a powerful ingredient in alignment.”
See also https://arxiv.org/abs/2505.13775
Chain of thought reasoning traces not related to final response 😬