


LLMs with mixture of millions of experts
DeepMind's new PEER technique enables LLMs to scale to millions of experts


Large language models (LLM) continue to improve when scaled with more parameters. But more parameters come with an explosion in computational and memory costs.
One of the methods to address computatational costs is “Mixture of Experts” (MoE). This technique enables increasing the size of LLMs and enables them to perform more tasks without increasing the computational costs of inference.
MoE modifies the fully connected layers of the transformer block, which account for most of the parameters in the model. MoE replaces the fully connected layers with several small "experts" that are specialized for specific types of tasks. For each input, only a few experts are activated, making the inference compute-efficient while keeping compute costs low. Popular models such as Mixtral, DBRX, Gemini, and possibly GPT-4 use MoE.
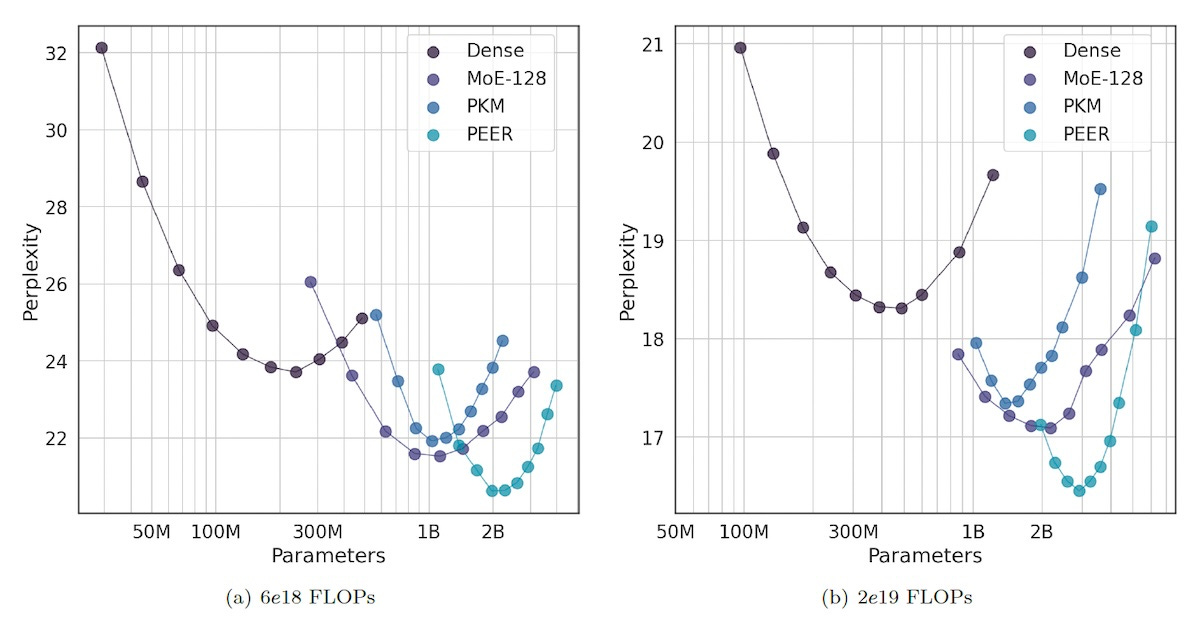
Recent research shows that increasing the number of experts can continue to yield improvements in the efficiency and accuracy of LLMs. However, current MoE techniques only support a limited number of experts.

DeepMind's new technique, Parameter-Efficient Expert Retrieval (PEER), enables transformers to scale to millions of experts.
PEER uses a "learned routing" mechanism to support millions of experts. It also uses a computationally efficient technique to shortlist candidates for each input before choosing the k experts to which it will route the input.
The PEER layer can be used as a drop-in replacement for dense layers. Experiments show that it outperforms dense layers and other MoEs both in perplexity score and computational efficiency, making it possible to get the most out of LLMs for a given token and compute budget.
According to the paper, PEER could potentially be combined with parameter-efficient fine-tuning (PEFT) techniques and adapted to select PEFT adapters at runtime, making it possible to dynamically add new knowledge and features to LLMs.
DeepMind doesn’t share details about its Gemini models, but PEER could possibly be one of the architectures used in the model.
Read more about PEER on VentureBeat.
Read the full paper on arXiv.
When discussing MoE, it's important to note that MoE itself is not an entirely new concept. Its theoretical foundation can be traced back to a 1991 paper by Michael Jordan, Geoffrey Hinton, and others. Despite having a history of over 30 years, it remains a widely applied technology today. For instance, personalized recommendations based on MoE are common in the field of recommender systems.
Key Features of MoE Models:
- Composed of multiple expert neural networks, each focusing on specialized subdomains of a larger problem space
- Includes a gating network to determine which experts to use for each input
- Experts can adjust different neural network architectures based on their specialties
- Training involves both experts and the gating network
- Can model complex and diverse datasets better than a single model
Advantages of MoE Models
In the realm of large models, it's like an old tree sprouting new branches. Let's look at the advantages of using MoE in large model domains:
- Improved accuracy through the combination of experts
- Scalability, allowing the addition of experts for new tasks/data
- Interpretability, as each expert focuses on a specific subdomain
- Model optimization as experts can have different architectures