
Multi-token prediction speeds up LLMs by up to 3X


Next-token prediction has proven to be a very effective method to train LLMs for complicated tasks. But next-token prediction also has limitations when it comes to multi-step reasoning tasks, and it also requires a lot more data to reach fluency levels that are comparable to humans.
A new paper by researchers at Meta suggests changing the transformer architecture to predict multiple tokens at the same time. The architecture shares the same transformer trunk and several output heads that each predict one token. This modification results in near-zero memory overhead while increasing inference speed and improving the model's performance on tasks that require long-horizon reasoning.
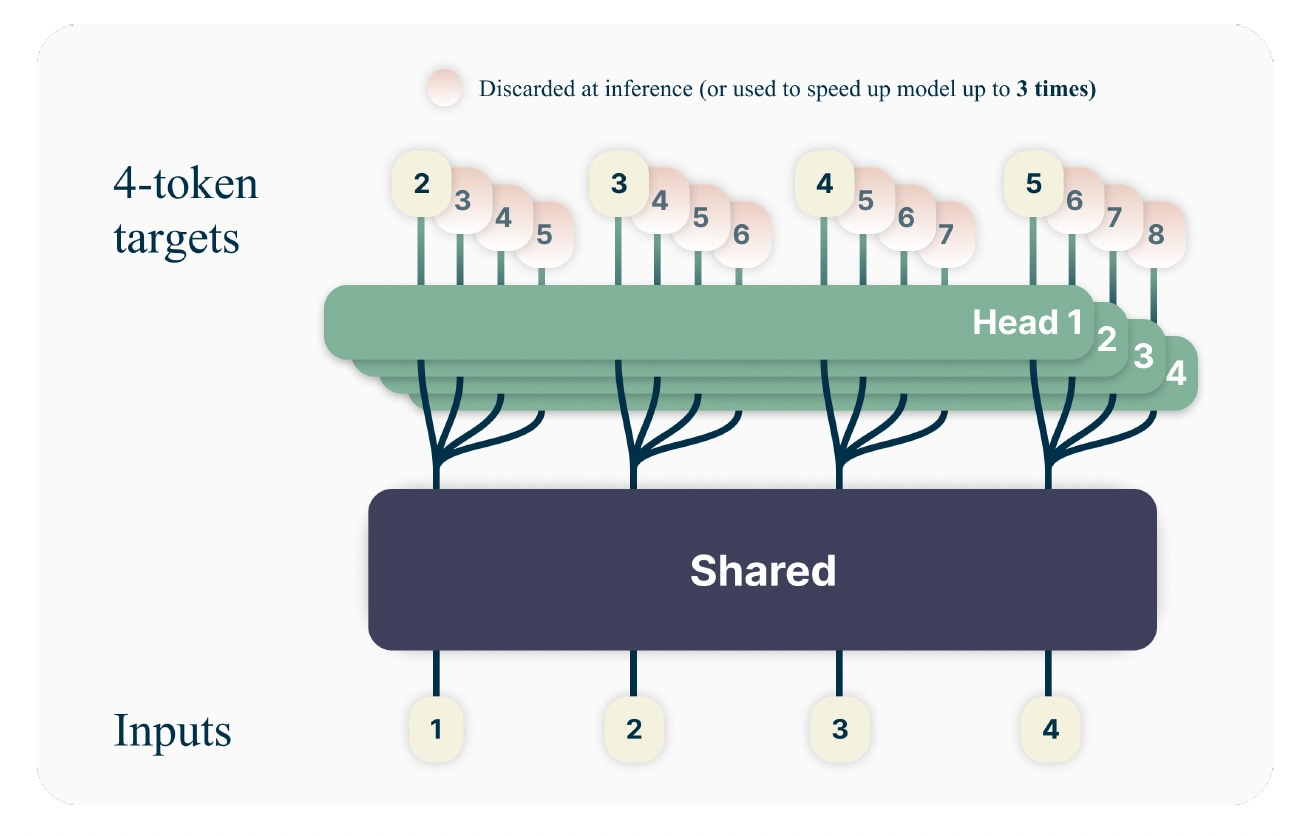
Multi-token prediction becomes more effective when applied to larger models. When applied to 6.7- and 13-billion models, it shows significant improvements on key benchmarks. Multi-token prediciton is also especially good for coding and single-byte tokenization tasks, where the vocabulary has not been determined in advance.
What's also appealing is that this optimization technique does not change the structure of the main transformer block, which means it can be orthogonal to other optimization techniques that make tweaks to the attention and feed-forward layers of the model. It will be interesting to see what the combination of these techniques will yield.
Read more about multi-token prediction on VentureBeat.
Read the paper on Arxiv.