
New RL technique makes diffusion LLMs viable contenders for reasoning tasks
Diffusion LLMs outperform autoregressive models in simple inference. Now they're getting reasoning abilities.


d1, a new reinforcement learning framework by Meta and UCLA, enhances the reasoning capabilities of diffusion-based large language models (dLLMs). dLLMs are different from autoregressive language models (e.g., GPT-4o and Llama) in the way they generate their responses.
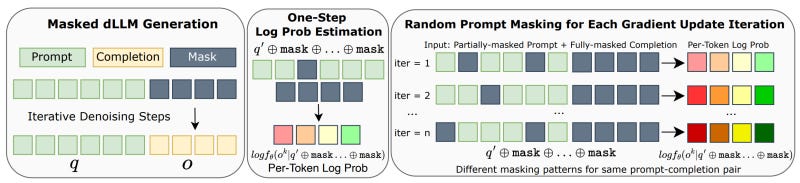
Autoregressive models predict one token at a time. In contrast, dLLMs start with a heavily masked version of the input text and "unmask" the response over several steps. The process is inspired by the original diffusion architecture used in image generation models such as DALL-E 2 and StableDiffusion. It allows dLLMs to consider the entire context simultaneously at each step as opposed to just focusing on the next token.
This difference allows dLLMs to use parallel processing during generation, which can make it much faster than autoregressive models. In some cases, dLLMs can result in 10x throughput advantages over classic LLMs.

However, one of the great challenges of dLLMs is chain-of-thought reasoning. Autoregressive LLMs can be trained for reasoning through reinforcement learning (RL) algorithms that reward or penalize the model based on its answer.
RL algorithms used for training LLMs (e.g., PPO and GRPO) calculate the log probability of the generated text sequence to guide the learning process. This method works for models that generate their answers token by token but does not apply to the parallel and iterative nature of dLLMs.
The d1 framework solves this with a two-stage post-training process:
First, the pre-trained dLLM is fine-tuned on a dataset of high-quality reasoning examples through supervised fine-tuning (SFT).
After SFT, the model undergoes RL training using diffu-GRPO, a new algorithm that adapts GRPO to dLLMs. diffu-GRPO uses an efficient method to estimate log probs without the costly computations of the original algorithm. It also uses a technique called "random prompt masking” that randomly masks parts of the input prompt in each update step of the training.
The researchers applied the d1 framework to LLaDA-8B-Instruct, an open-source dLLM, and compared multiple versions: the base LLaDA model, LLaDA with only SFT, LLaDA with only diffu-GRPO, and the full d1-LLaDA (SFT followed by diffu-GRPO).
Full d1-LLaDA outperformed other models on mathematical reasoning benchmarks (GSM8K, MATH500) and logical reasoning tasks (4x4 Sudoku, Countdown number game).
Interestingly, models showed "aha moments," especially on longer reasoning tasks, suggesting that the model develops reliable problem-solving strategies as opposed to memorizing answers.
In the future, the team plans to innovate at both the algorithmic and system levels to improve the efficiency of RL finetuning and accelerate the decoding process in LLMs.