
RePo provides an innovative solution to long-context tasks in LLMs
RePo, Sakana AI’s new technique, solves the "needle in a haystack" problem by allowing LLMs to organize their own memory.


A new technique developed by researchers at Sakana AI, called Context Re-Positioning (RePo), allows Large language models (LLMs) to dynamically re-organize their internal view of their input data to better handle long-context tasks.
LLMs process information in a strictly linear fashion, reading input from left to right regardless of the content’s actual structure. While this mimics how humans read a novel, it fails to capture the complexity of real-world data such as coding repositories, databases, or scattered documents in a retrieval-augmented generation (RAG) pipeline.
The core friction in current architectures lies in how they handle position. To handle their input sequences, LLMs must assign a position value to each token. Standard methods like Rotary Positional Embedding (RoPE) assign a fixed integer index to every token in the sequence. These methods rely on a “locality bias,” assuming that information physically closer together in the input stream is more semantically relevant. While this holds true for simple chat interfaces, it breaks down in complex tasks where the answer to a user’s query might be buried thousands of tokens away in a retrieved document.
This rigidity creates what the researchers describe as “extraneous cognitive load.” Drawing on cognitive load theory, the paper argues that forcing a model to track the arbitrary physical distance between related concepts wastes finite “working memory” (attention capacity). Instead of focusing on reasoning, the model spends resources managing the presentation of the data. RePo aims to eliminate this waste by allowing the model to virtually “move” tokens closer together in the mathematical space used for attention, without changing their actual order in the input text.
How RePo works
RePo introduces a lightweight, differentiable neural network module that sits before the model’s attention mechanism. Instead of using a pre-defined integer sequence (0, 1, 2…), this module predicts a scalar position value based on the content of the token itself. By analyzing the “what” (the token’s hidden state) the module determines the “where.” This allows the model to project tokens into a continuous mathematical space where semantically related items are clustered together, effectively shortening the distance the attention mechanism must traverse.
The training process for RePo is straightforward because the module is fully differentiable. It is optimized jointly with the rest of the model using standard backpropagation. Because the assigned positions are continuous real values rather than fixed integers, the model can adjust them granularly to minimize the standard next-token prediction loss. This means the model isn’t explicitly taught how to organize data; instead, it discovers the optimal organization strategies on its own (e.g., as clustering related concepts) simply as a way to predict the next token more accurately during training on general data.
In comments provided to TechTalks, paper co-author Huayang Li explained that this mechanism allows the model to combat the limitations of recency bias. “RePo has the potential to alleviate [recency bias] by dynamically assigning closer positions to relevant information,” Li said. This shift moves the architecture from a passive reader that accepts the input order as truth, to an active organizer that restructures data to minimize the loss in next-token prediction.
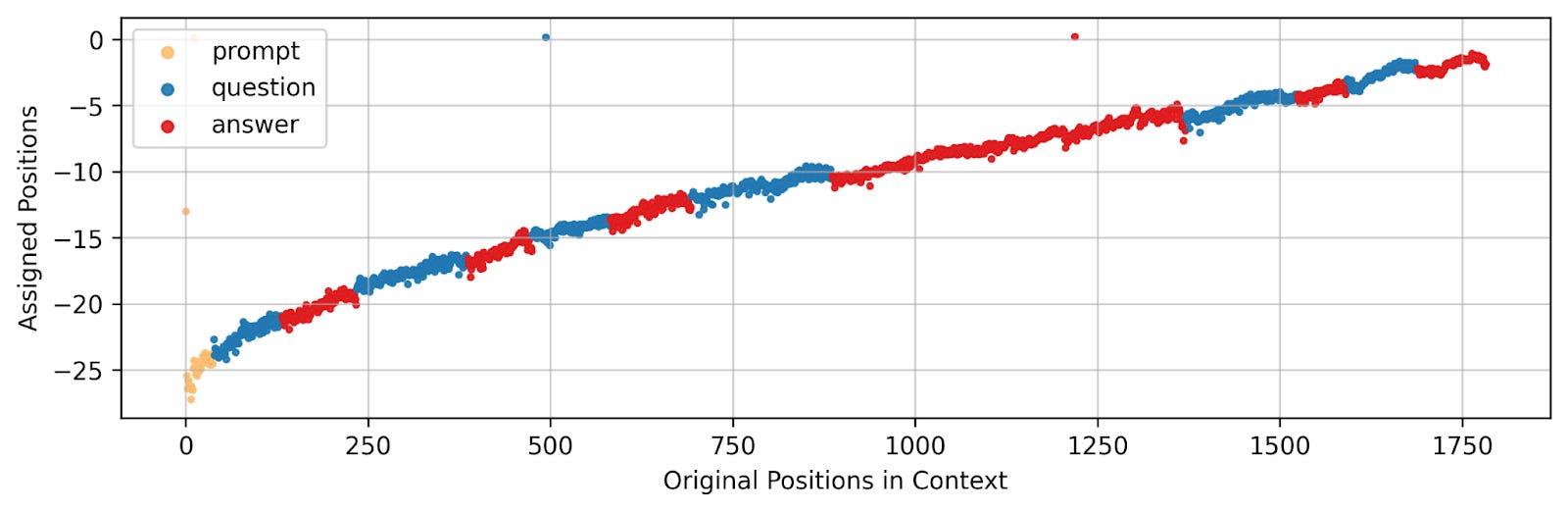
The flexibility of RePo leads to surprising emergent behaviors where the model invents its own organizational schemes. In one visualization from the paper, the model physically clustered the “prompt,” “question,” and “answer” tokens together in the positional space, even though they were separated by long passages of text. The researchers also observed a “mirror effect,” where the model assigned negative position values, effectively learning to count backwards or rotate in a reverse direction to better capture relationships in the data.
These patterns suggest that when given the freedom, models prefer non-linear structures. Li noted that this adaptability is particularly visible when processing structured data. “When the input is a table, the model can adaptively learn positional assignments that segment table rows,” he said. The model recognizes that a cell in Row 1 is related to the corresponding cell in Row 2 and assigns them similar positional values, reconstructing the table’s structure that is usually lost when flattened into text.
RePo in action
To validate the technique, the researchers applied RePo to an OLMo-2 1B backbone and evaluated it against standard baselines. The most significant gains appeared in tasks involving “noisy” context, where the model must identify relevant facts hidden among irrelevant information. On the RULER benchmark, which tests long-context understanding, RePo outperformed standard RoPE models by over 11 points on variable tracking tasks.
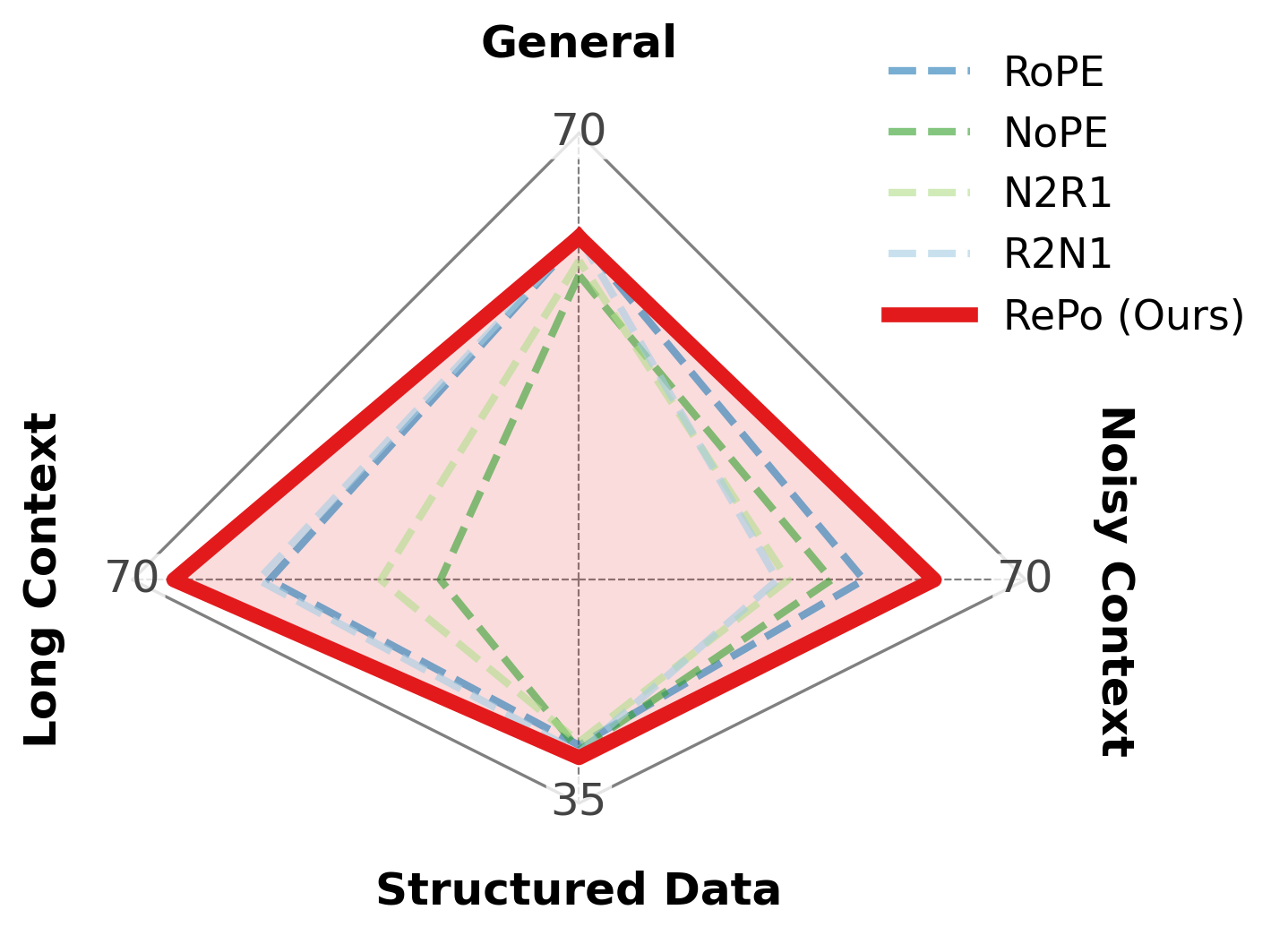
This improvement is not merely a result of the model learning to ignore noise. According to Li, RePo actively highlights the signal. “RePo is able to assign more attention to the most critical ‘needle’ tokens in a noisy context compared with standard attention mechanisms,” Li said. By assigning these critical tokens distinct positions, the model prevents them from being drowned out by the surrounding text, effectively solving the “needle-in-a-haystack” problem at the architectural level.
The model also demonstrated strong extrapolation capabilities. Although trained on a context length of 4,000 tokens, RePo maintained high accuracy when tested on contexts up to 16,000 tokens. In Question Answering (QA) tasks over these extended lengths, the method outperformed RoPE and other baselines by more than 13 points. This suggests that the learned positional strategies generalize better to unseen lengths than fixed arithmetic progressions.
Engineering implications
For developers looking to implement RePo, the technique offers a path to upgrade existing models without starting from scratch. The module adds only 0.9% to the total parameter count and is compatible with standard inference optimizations like FlashAttention and vLLM. This means engineering teams can integrate RePo into high-throughput production pipelines without sacrificing speed.
However, the method is not without challenges. Li warned that simple supervised fine-tuning (SFT) is insufficient to instill these positional strategies. Implementing RePo requires a specific training regimen known as “Continual Pre-Training” (CPT). Unlike simple fine-tuning which might use a small targeted dataset, CPT involves resuming the training of a pre-existing checkpoint (like OLMo-2) on a massive amount of general data. “Based on our recent experiments with 1B and 7B models, CPT on more than 50B tokens yields significantly better results,” Li said.
As AI systems evolve toward agentic workflows that manage massive, long-term contexts, techniques like RePo may become essential components of the stack and help organize memory.
“I view RePo as orthogonal to agentic systems,” Li said. “However, a ‘memory sorting’ mechanism could serve as additional information that benefits long-context management in such systems.”