
Unpacking Gemma 4’s multi-token prediction (and why you should care)
How Gemma 4’s multi-token prediction and community-driven DFlash are speeding up local LLM throughput by 3-6x.


Google just made a major upgrade to its Gemma 4 family of open-weight LLMs that significantly improves the inference speed of the models.
By integrating multi-token prediction (MTP) into its architecture, Gemma 4 breaks away from the traditional one-token-at-a-time approach, increasing throughput on consumer-grade hardware.
The efficiency of an LLM is often constrained by memory bandwidth rather than raw computational power. In standard autoregressive generation, a model predicts the next token, appends it to the sequence, and repeats the process. This requires moving the model’s massive weight matrices from memory to the processor for every single word. On local devices like MacBooks or PCs with limited VRAM speeds, this “memory wall” creates a hard limit on how fast the model can respond, regardless of the GPU’s clock speed.
Multi-token prediction changes this dynamic by predicting several tokens in parallel. Instead of asking the model “What is the next token?”MTP asks “What are the next n tokens?” By predicting multiple tokens at once, Gemma 4 leverages the parallel processing capabilities of modern GPUs more effectively, reducing the number of times the model weights must be fetched from memory. This results in a direct performance boost for the end user, making local interactions feel more instantaneous and fluid.
How multi-token prediction accelerates inference
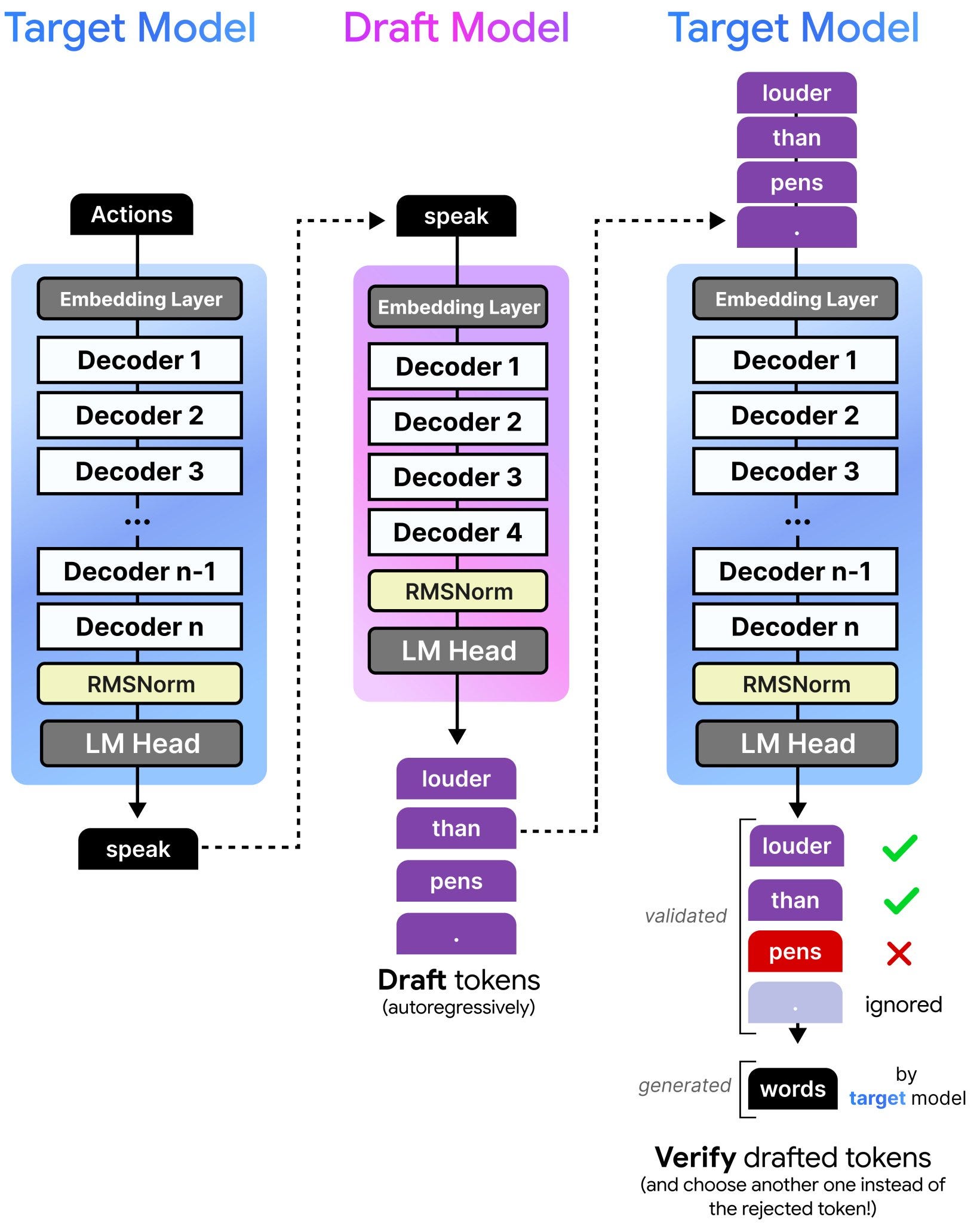
To understand how Gemma 4 achieves this speedup, it is helpful to view the system as a partnership between a fast “drafter” and a high-quality “target” model. In a standard setup, the target model (i.e., the massive neural network containing the bulk of the parameters) does all the heavy lifting for each token it produces.
In Gemma 4, the architecture includes smaller, specialized models that act as drafters. These drafters work ahead of the main model, guessing what the next few tokens might be.
Once the drafter proposes a sequence of tokens, the main model reviews them in a single pass. This is a form of parallel processing; because the main model already has the suggested tokens, it can use its “attention” mechanism to verify them all at once. Attention is the mathematical process the model uses to weigh the importance of different tokens in a prompt to understand context. Because verifying a sequence is computationally “cheaper” than generating it from scratch, the main model can confirm the entire sequence in roughly the same time it would normally take to generate just one token.
This verification process is not an “all-or-nothing” deal. If the drafter suggests four tokens and the main model agrees with the first three but finds the fourth unlikely, it accepts the three correct ones, generates its own fourth token, and then restarts the drafting process. This ensures that while the speed increases, the quality of the output remains identical to a traditional model. The user gets the intelligence of the large model with the speed of the smaller drafter.

Experiments show that you can get up to 3x acceleration on both on-device and the larger versions of Gemma 4.
Managing the overhead of speculative drafting
Implementing MTP is not without its costs. Running additional drafter heads requires extra compute and memory. Google addressed this memory tax through an architecture that shares resources between the main model and the drafters.
A key component of this is KV cache sharing. The Key-Value (KV) cache is the model’s short-term memory. It stores the attention values of previously seen tokens so the model doesn’t have to re-calculate them for new tokens. By allowing the main model and the drafters to use the same cache, Gemma 4 avoids duplicating data in the VRAM.

Another optimization involves “shared target activations.” The drafters do not start their predictions from a blank slate. Instead, they use the internal representations (the “activations”) already calculated by the main model’s deeper layers. This means the drafters are essentially piggybacking on the work the main model has already done.
Additionally, the smaller Gemma 4 models (E2B and E4B) have an “efficient embedder” feature that further reduces the memory costs. Normal LLMs have a matrix that maps the activations to the entire token space (around 260,000 for Gemma 4). Efficient embedders use clustering methods that summarize groups of related tokens into a smaller space, which reduces the size of the projection matrix and keeps the drafter heads extremely lightweight.
However, MTP comes with a potential compute penalty. If the drafter is not well-aligned with the target model and produces sequences that are consistently rejected, the system actually becomes slower. Every rejected draft represents wasted GPU cycles that could have been used for standard generation. This is why the drafters in Gemma 4 are trained specifically to align with the main model, ensuring a high acceptance rate. Without this alignment, the overhead of the MTP heads would outweigh the benefits of parallel verification.
Beyond MTP: DFlash and block diffusion
The open nature of Gemma 4 has already allowed the research community to push its performance limits further. The team at Z-Lab have integrated a technique called DFlash with Gemma 4, achieving even higher inference speeds.
DFlash optimizes the way the GPU handles the model’s computations, targeting the bottlenecks in the KV cache and the attention layers that MTP doesn’t solve on its own. Experiments show that DFlash can increase the speed of Gemma 4 by up to 6x.
DFlash incorporates a concept known as “Block Diffusion.” While MTP still works by predicting tokens one at a time, Block Diffusion treats the generation process more like an image generator might. It works with “blocks” of representations in the embedding space. Instead of just guessing the next token, the model refines a whole block of information simultaneously. This approach differs from MTP by moving away from strictly sequential logic to a more holistic, parallel refinement of the output.
The results on Gemma 4 show that these combined techniques can significantly reduce latency. By optimizing the underlying GPU kernels (the low-level code that tells the hardware how to perform math), DFlash ensures that the memory transfers are as efficient as possible. This community-driven improvement demonstrates that the baseline performance of Gemma 4 is just a starting point; the architecture is flexible enough to accommodate advanced optimization layers that weren’t part of the original release.


Why open weights are the engine of AI progress
The rapid development of DFlash for Gemma 4 highlights the practical benefits of open-source AI. When a model is released with open weights and a documented architecture, it ceases to be a static product and becomes a platform for innovation. Researchers can inspect how the MTP heads interact with the main trunk of the model, allowing them to write specialized code that optimizes those specific pathways.
The integration of DFlash would have been impossible if Gemma 4 was released as an open model with an Apache 2.0 license. The community would be limited to using the model as provided by Google, with no way to tweak it for specific hardware or edge-case applications. Open weights allow for a crowdsourced R&D department where thousands of independent developers can work on making a model faster, smaller, or more accurate. This ecosystem accelerates the transition of AI from giant data centers to everyday devices like smartphones and laptops.
Unfortunately, the current dynamics of the market encourage frontier labs to keep most of their models and the details of their architecture and training secret. However, the activity surrounding Gemma 4 suggests that the future of AI is not just about the size of the model, but the transparency of its design.
As more developers build on these open foundations, the gap between “research grade” and “daily use” AI continues to shrink. By sharing the underlying technology, Google has provided the blueprints for the community to make AI more accessible and efficient for everyone.
“In Gemma 4, the architecture includes smaller, specialized models that act as drafters. These drafters work ahead of the main model, guessing what the next few tokens might be.”
this is really cool. i love seeing all the harness/platform improvements outside the model itself.