


What do vision language models really "see"?
Vision-language models (VLMs) score high on competitive multi-modal benchmarks but fail on basic visual acuity tests, according to a new study.


Vision language models (VLMs) have displayed impressive performance at tasks that require understanding both text and images. But do these models really “see” the images like humans do, or are they relying on other cues to solve these tasks?
A new study by researchers at Auburn University and the University of Alberta shows that despite their impressive performance on benchmarks, VLMs struggle with visual tasks that are surprisingly simple for humans. The researchers developed BlindTest, a suite of seven visual tasks that are “absurdly easy for humans.” Surprisingly, their findings show that four state-of-the-art VLMs struggle “with tasks that can be easily solved by a five-year-old.”
This can have implications for using VLMs in real-world applications and can guide future directions of research and development in the field.
Current benchmarks mask VLM limitations
The impressive performance of VLMs on popular benchmarks has led to their exploration in various applications. However, the new study argues that existing benchmarks do not adequately evaluate whether VLMs truly understand the visual information they process.
Current VLM benchmarks include a wide range of tasks, but they primarily focus on measuring the overall performance gap between humans and LLMs. They often fail to pinpoint the specific visual limitations of these models, which is crucial for guiding future vision research.
“The biggest shortcoming might be that, in some popular benchmarks, many questions can be answered by models even without using the input image,” Anh Nguyen, co-author of the paper and Associate Professor of Computer Science at Auburn University, told TechTalks.
For example, Google’s Gemini can correctly answer 42% of the questions in the popular MMMU multi-modal benchmark without seeing the input image. A similar phenomenon is observed in document benchmarks.
“In other words, some benchmarks don’t accurately test a model’s ability to ‘see’ the input image—they simply assess the model’s ability to provide correct answers, which can often be memorized from extensive reading of Internet text,” Nguyen said.
This over-reliance on textual cues and memorized information raises concerns about the actual visual processing capabilities of VLMs.
“Current benchmarks overlook a key question: Do VLMs perceive images like humans do?” the researchers write.
BlindTest: A reality check for VLMs
To evaluate the true visual perception capabilities of VLMs, the researchers developed BlindTest, a suite of seven visual tasks designed to assess the models’ ability to perceive basic geometric shapes and spatial relationships.
The researchers drew inspiration from the “visual acuity” tests used by optometrists to measure human vision. They created tasks that involve simple 2D geometric primitives such as lines, circles, and squares, presented on a blank canvas. The tasks require minimal to no world knowledge and focus solely on basic visual perception skills.
“We were initially working with maps and directed graphs and found vision language models (VLMs) to perform poorly on this type of data,” Nguyen said. “We decided to understand this interesting phenomenon by stripping down the images to the simplest form that still causes VLMs to struggle. And there came BlindTest.”
Some of the tasks in BlindTest include:
- Counting the number of intersections between lines or circles
- Determining whether two circles are touching
- Identifying letters that are encircled
- Counting overlapping shapes
- Counting nested squares and grid squares
- Following colored paths
“We hypothesize that VLMs will struggle because, while the primitives are well-known, their exact spatial information… on a white canvas is typically not describable in natural language, even for humans, and therefore requires a ‘visual brain’ to perceive,” the researchers write.
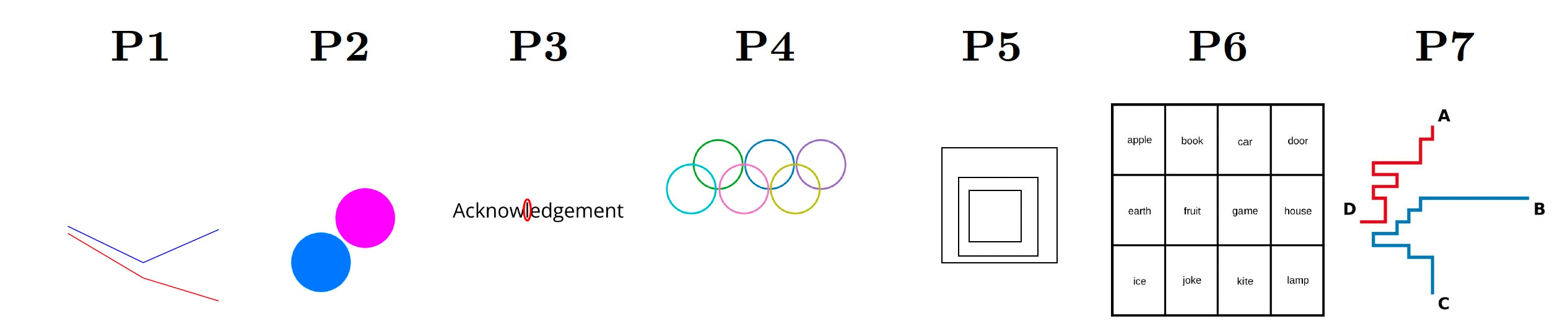
VLMs struggle with simple visual tasks
The researchers evaluated four state-of-the-art VLMs on BlindTest: GPT-4o, Gemini 1.5 Pro, Claude 3 Sonnet, and Claude 3.5 Sonnet. These models represent some of the highest-performing VLMs on recent multimodal benchmarks.
Despite their strong performance on existing benchmarks, all four VLMs struggled on the BlindTest tasks.
“The most important finding is that, on average, four state-of-the-art VLMs are only 58.57% accurate on these simple, low-level visual tasks that humans are expected to score 100%,” Nguyen said.
For example, the models struggled to determine whether two lines or circles intersect, especially when they were close together. They also had difficulty identifying circled letters when the circle overlapped the letter. And surprisingly, the VLMs even struggled to count the number of rows and columns in an empty grid, a task that humans find trivial.
“Our experiments provide the impression that the vision of VLMs is surprisingly like that of an intelligent person but with myopia, perceiving fine details as blurry,” the researchers write.
The need for more robust VLM benchmarks and architectures
“There are two implications of this finding,” Nguyen said. “(1) The community should be cautious of using VLMs on tasks outside of the areas that they have been thoroughly tested on regardless of how simple the tasks are; (2) there could be a major common architecture limitation across these VLMs that is responsible for this poor accuracy.”
Most VLMs use “late fusion,” where separately trained language and vision modules extract the features of the input images and text and concatenate them. This approach might prevent the models from effectively integrating visual and textual information.
“[With] the existing ‘late fusion’ approach, VLMs do NOT get to see the question, while extracting visual features from the image,” Nguyen said. “After that, given the already-extracted visual features, models read the question for the first time and try to answer it. Ideally, VLMs should LOOK at the question while extracting visual features from the image.”
Research shows that biological brains adjust their attention based on intention and goals. It is natural to expect that VLMs should benefit from “early fusion,” where text and visual features are extracted together by a unified model. Meta is taking this approach with its latest multi-modal model Chameleon. Other AI labs are reportedly working on similar models. It will be interesting to see if they will move the needle on BlindTest.
There is still a lot to learn in this field. Nguyen says that the researchers will be exploring how to make VLMs perform better on the BlindTest benchmark. They will also work on methods for “visualizing what models actually ‘see,’ which is intriguing to figure out given their poor accuracy.”