
What (I think) makes Gemini 3 Flash so good and fast
Google didn’t reveal a lot of information about its new Flash model. So we had to speculate a lot on what is going on under the hood.


Google has just released Gemini 3 Flash, a lightweight, efficient tool optimized for speed and low latency, capable of delivering performance comparable to the larger Gemini 3 Pro at a fraction of the cost. Google brands it as the democratization of frontier intelligence. On the surface, Gemini 3 Flash appears to be a standard upgrade in the race for efficient AI: a smaller, faster model distilled from its larger sibling.
However, a closer look at independent benchmarks and leaked architectural details suggests that Gemini 3 Flash is not simply a small model. We are likely looking at a massive, trillion-parameter architecture behaving like a lightweight agent through extreme sparsity, a design choice that brings unprecedented power but introduces specific tradeoffs in token efficiency and reliability. (Lots of speculation incoming.)
The ultra-sparse secret
Google officially confirms that the model’s architecture relies on the Gemini 3 Pro foundation, which uses a transformer-based sparse mixture-of-experts (MoE) design. In standard MoE systems, a router dynamically directs input tokens to specialized “experts” or sub-networks. This activates only a subset of parameters for any given inference, decoupling the model’s total capacity from its computational cost.
While Google remains tight-lipped about parameter counts, a November 2025 Reuters report provided a crucial piece of the puzzle. The report detailed a potential licensing deal between Apple and Google for a 1.2 trillion-parameter model intended to power Siri in 2026. Expert speculation posits that Gemini 3 Flash matches this profile: a 1.2T parameter “ultra-sparse” model.

The distinction between “sparse” and “ultra-sparse” defines the model’s capabilities. An ultra-sparse architecture scales the number of experts dramatically while keeping the active parameter count low. Speculations suggest that while Gemini 3 Flash may house over a trillion parameters of knowledge, it activates only 5 to 30 billion parameters per inference. This allows the model to access a massive reservoir of memorized information while maintaining the inference speed and cost profile of a much smaller system.
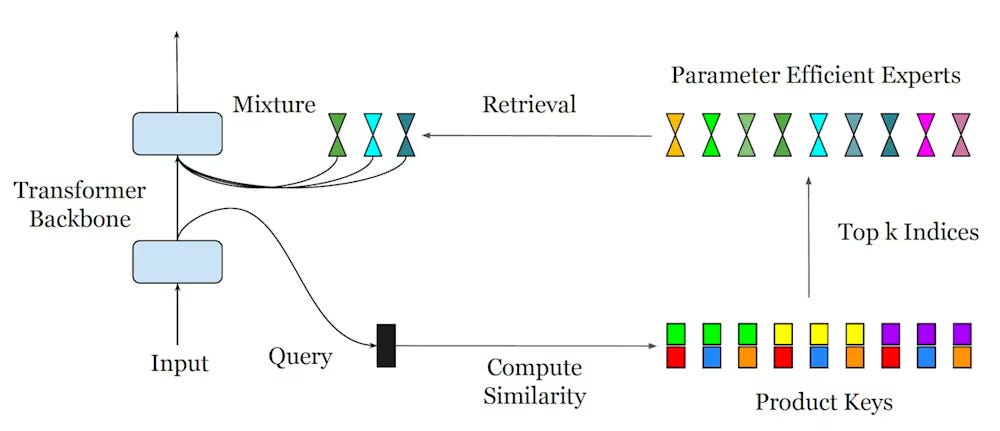
But how can you create a model with a massive number of experts? In 2024, DeepMind released a paper that did not get much attention. It had a single author but proposed a very interesting technique called Parameter Efficient Expert Retrieval (PEER) that can scale MoE architectures to millions of experts, further improving the performance-compute tradeoff of LLMs.
PEER replaces the fixed router of the classic MoE with a learned index that can efficiently route input data to a vast pool of experts. For each given input, PEER first uses a fast initial computation to create a shortlist of potential candidates before choosing and activating the top experts. This mechanism enables the MoE to handle a very large number of experts without slowing down. While there is no evidence about it, I have a strong feeling that Gemini 3 Flash is using PEER or some elements of it.

Augment Code provides code reviews that understand context, not just diffs. Learn more here.
The ‘thinking’ tax
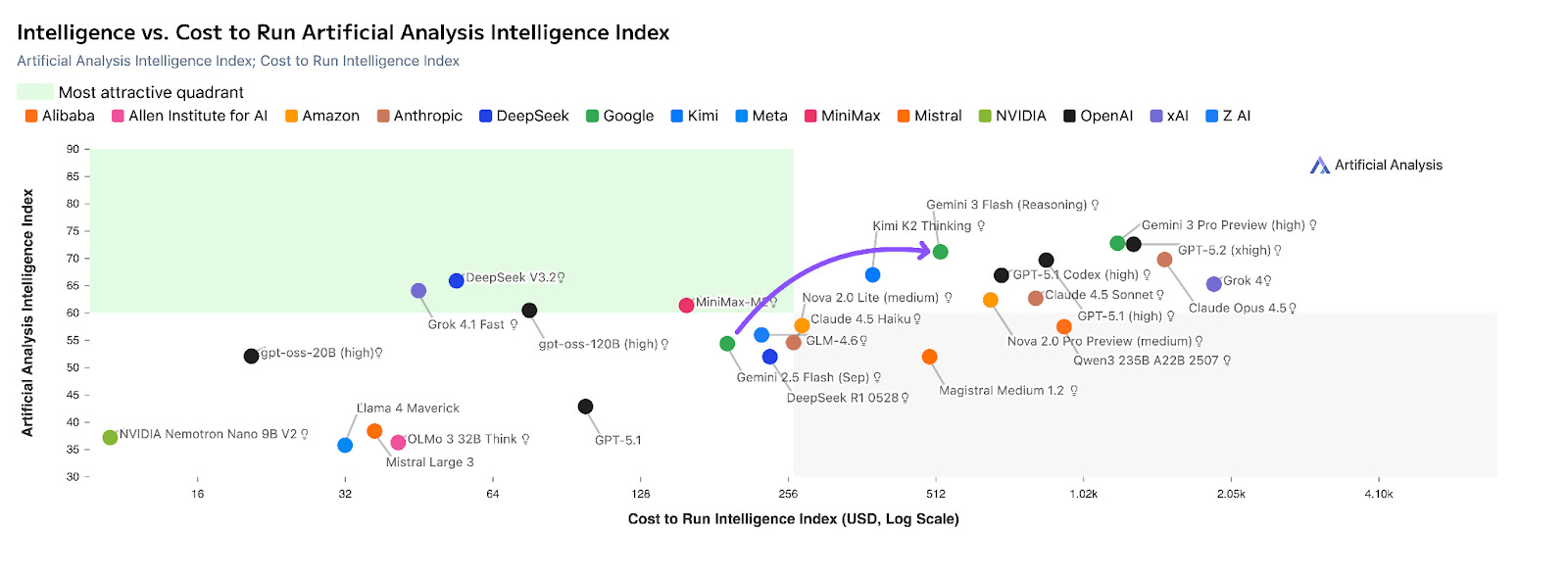
This architecture places Gemini 3 Flash in a unique market position. On the Artificial Analysis Intelligence Index, the model ranks third, trailing only Gemini 3 Pro and GPT-5.2 High (and ahead of the highly touted Claude Opus 4.5). It offers the highest intelligence-per-dollar ratio currently available. However, this intelligence comes with a hidden “tax” in the form of token bloat.


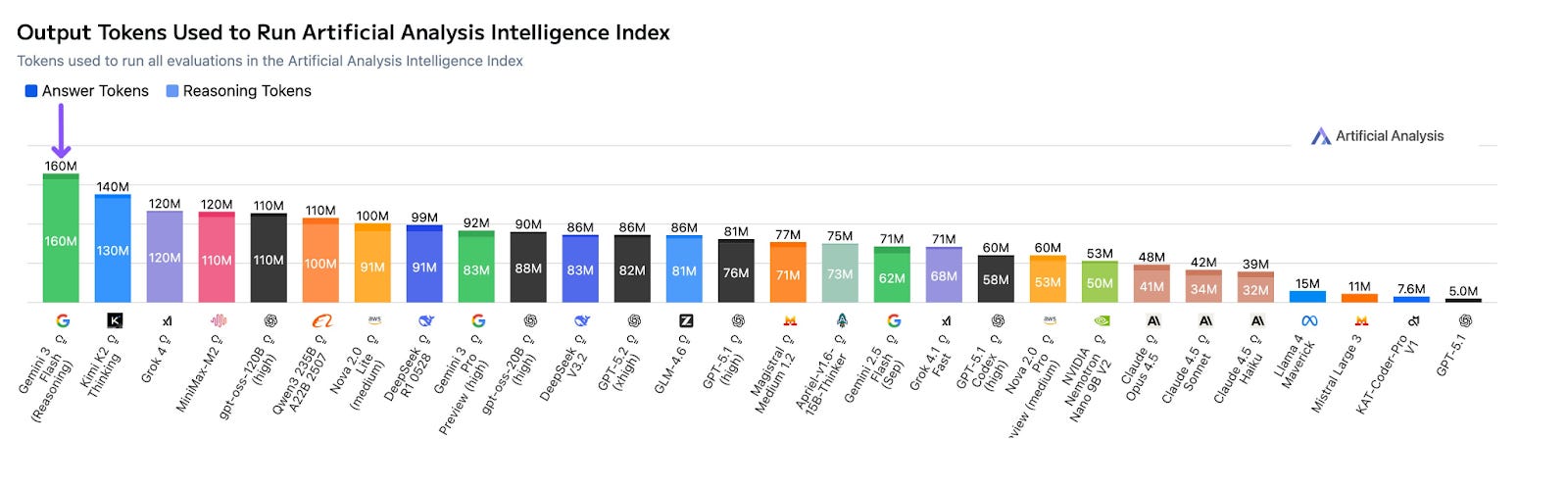
To achieve high reasoning performance with low active parameters, the model appears to rely on verbose internal processing. Google notes that the model can “modulate” its thinking, extending computation for complex tasks. Independent testing reveals the magnitude of this behavior: Gemini 3 Flash uses approximately 160 million output tokens to complete the Artificial Analysis benchmark suite. This is more than double the token usage of its predecessor, Gemini 2.5 Flash.
For developers, this impacts the value equation. While the price per token is low ($0.50/$3 per 1 million input/output tokens), the model requires more tokens to solve the same problems compared to denser architectures. It is a “chatty” model internally, trading brevity for reasoning depth. Furthermore, it is 22% slower than the previous Gemini 2.5 Flash generation.
But despite its high token use, Gemini 3 Flash Preview is still the most cost efficient model for its level of intelligence.
The hallucination problem
Gemini 3 Flash also has a special profile on factuality. The model achieves the highest score on the AA-Omniscience benchmark, which measures knowledge accuracy. This validates the theory of a massive underlying parameter count; the model “knows” more facts than almost any other system.
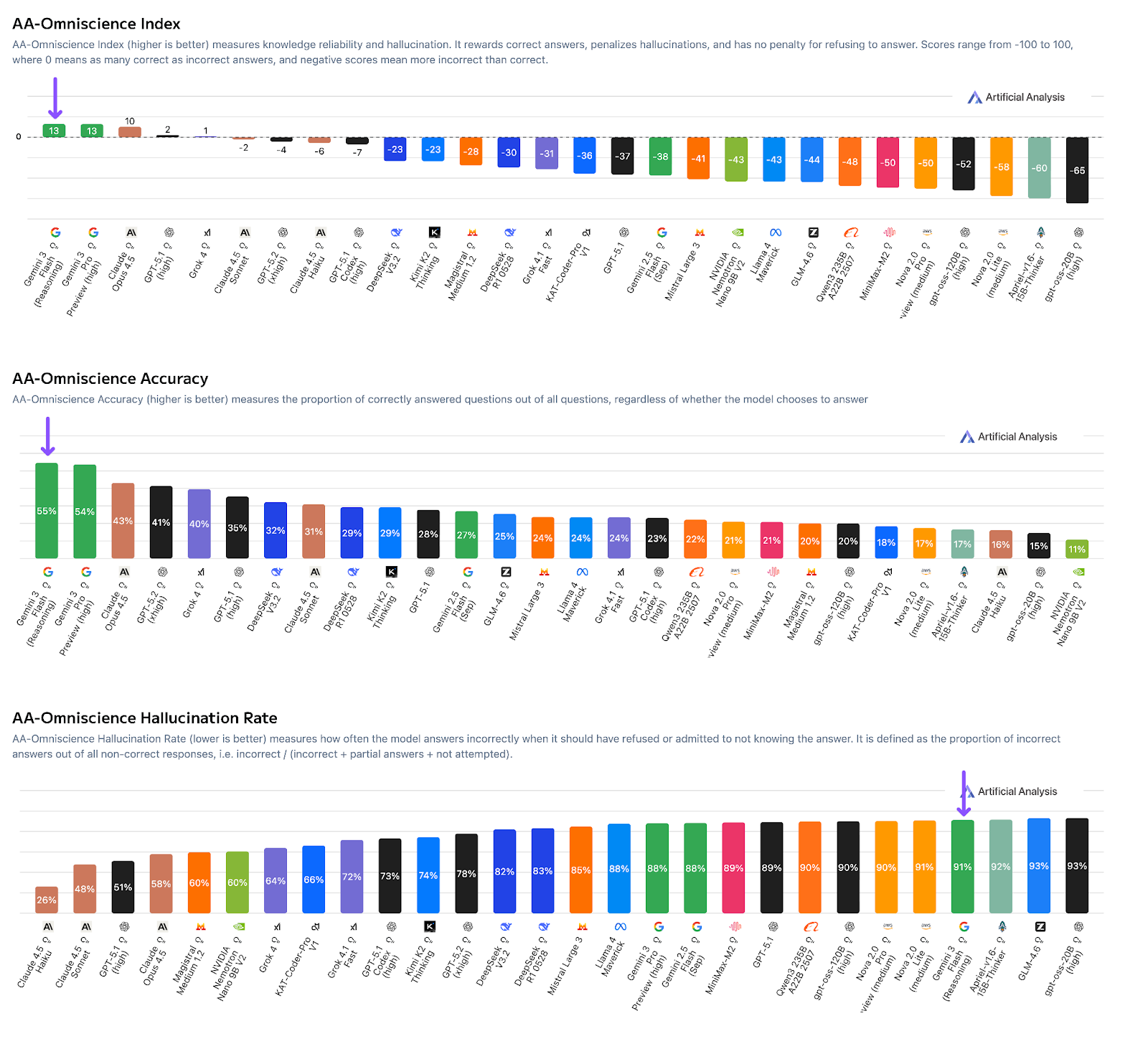
However, this extensive knowledge base creates a confidence problem. The model exhibits a 91% hallucination rate on refusals. When faced with questions it does not know the answer to, Gemini 3 Flash rarely admits ignorance. Instead, it attempts to generate a plausible answer. This is a critical regression compared to Gemini 3 Pro and even the older 2.5 Flash. For real-world applications where “I don’t know” is a necessary safety valve, this tendency poses a significant risk.
A new default with caveats
Google has moved aggressively to make Gemini 3 Flash the standard, making it the default model in the Gemini app on the “Fast” and “Thinking” mode (the “Pro” mode uses the larger Gemini 3 Pro model). Its ability to handle multimodal inputs without separate preprocessing makes it a powerful engine for consumer-facing applications like real-time video analysis or mobile agents.
There is no perfect answer when it comes to choosing models. I still use Gemini 3 Pro knowledge-intensive tasks that require factual accuracy, such as cleaning up complex transcripts that have technical terms (Gemini 3 Pro is very good at filling the holes and using the context and its vast internal knowledge). It is also superior for one-shot coding tasks that require extensive processing of existing code. But for most other things, Gemini 3 Flash is a really good model.
Gemini 3 Flash proves that we can make a trillion-parameter model fast and cheap, but we cannot yet make it perfect.
“It offers the highest intelligence-per-dollar ratio currently available. However, this intelligence comes with a hidden “tax” in the form of token bloat.”
great call out.
i will say gemini flash is probably my favorite model right now. is does feel like a pro model at flash speed..
The 91% hallucination rate on refusals is the buried lead here, and I'm surprised it's not getting more attention given that it's a regression from prior versions. An ultra-sparse MoE activating 5-30B of 1.2T parameters sounds like it should have more retrieval robustness, not less — so the failure mode seems like it's in the routing, not the raw capacity. Is this a training objective problem (the model wasn't rewarded for expressing uncertainty) or does the sparsity architecture itself create conditions where low-confidence signals don't propagate reliably through whichever expert path gets activated? That distinction matters a lot for whether Google can fix this through post-training or whether it's architectural.