
What is reinforcement learning from human feedback (RLHF)?

Since OpenAI released ChatGPT, there has been a lot of excitement about advances in large language models (LLM). While ChatGPT is around the same size as other state-of-the-art LLMs, its performance is far superior. And it already promises to enable new applications or disrupt old ones.
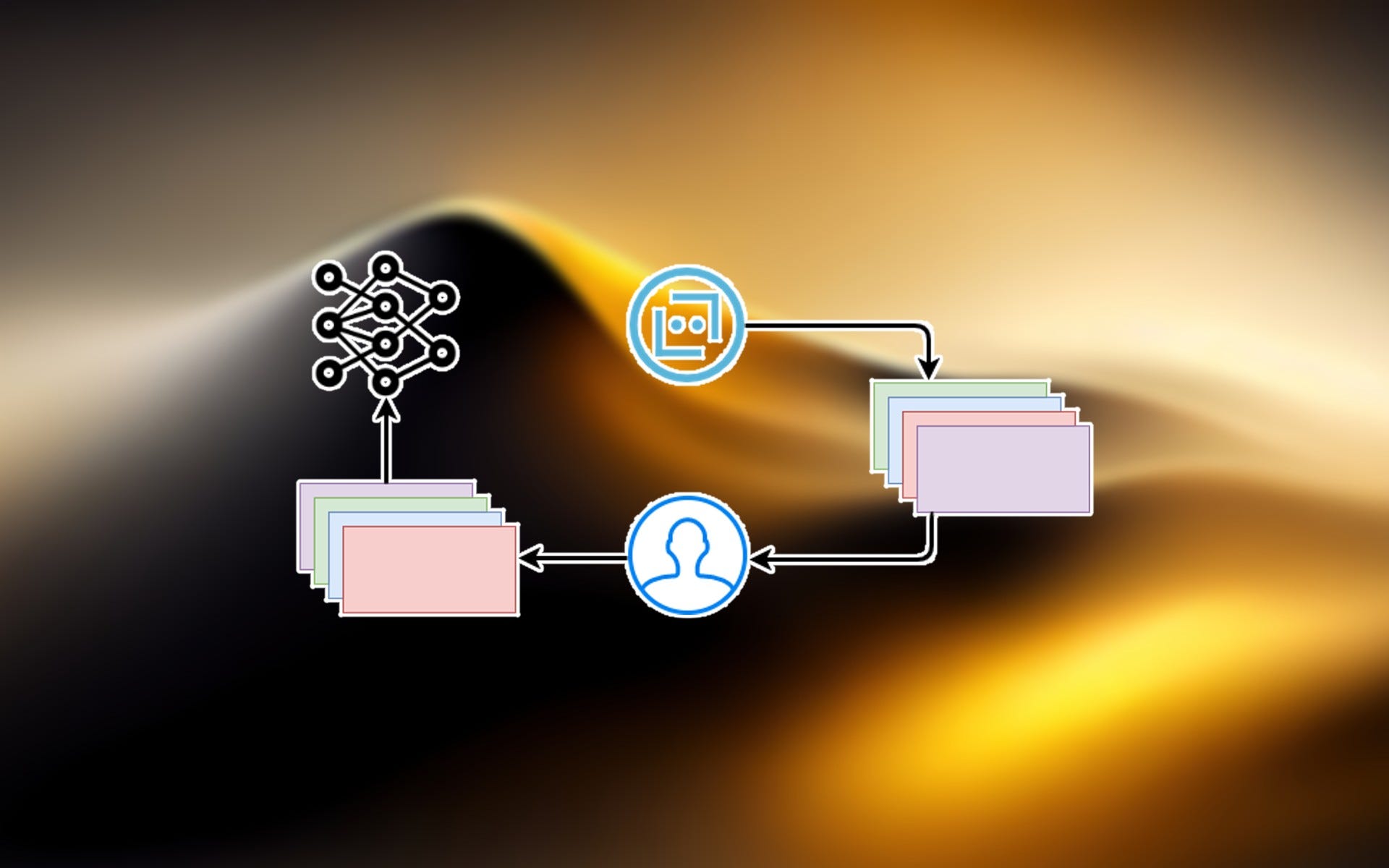
One of the main reasons behind ChatGPT’s amazing performance is its training technique: reinforcement learning from human feedback (RLHF). While it has shown impressive results with LLMs, RLHF dates to the days before the first GPT was released. And its first application was not for natural language processing.
Read everything to know about RLHF and how it applies to large language models on TechTalks.
For more AI explainers:
Brilliant. The feedback loop remind me of optimising my bike routes. Human input is key.