
What we know so far about Gemini 2.5 Deep Think
A look inside Google’s Gemini 2.5 Deep Think, the AI that uses extended "slow thinking" to solve complex math and code problems.


Google has released its new large reasoning model, Gemini 2.5 Deep Think, which extends its “thinking time” by scaling its inference compute, which allows it to tackle difficult problems through parallel branches. This approach powered a version of the model to a gold-medal standard at the International Mathematical Olympiad (IMO).
The newly released model is a faster variant that, while less capable, still achieves Bronze-level performance on the 2025 IMO benchmark.
A parallel approach to reasoning
Deep Think’s method is partly inspired by human cognition. The model uses parallel thinking techniques to generate and consider many ideas at once. Instead of following a single path, it explores “deeper chains of thought and parallel chains of thought that can integrate with each other,” according to Jack Rae, Research Scientist at Google DeepMind, who spoke about Deep Think at the AI Engineer World’s Fair in July.
For example, when solving a math problem, it might simultaneously explore a proof by contradiction while also testing solutions based on Rolle’s theorem and Newton’s inequalities. The system can then revise or combine these different ideas before settling on a final answer. To ensure the model effectively uses this extended thinking time, Google developed new reinforcement learning techniques that encourage it to make use of its extended reasoning paths. (Unfortunately, there are no details on the new RL algorithm, which seems to be the key component behind Deep Think’s superior performance on reasoning problems.)
Under the hood of gemini 2.5
The Gemini 2.5 family, including Deep Think, is built on a “sparse mixture-of-experts” (MoE) transformer architecture, also used in other reasoning models such as DeepSeek-R1. This design is key to its efficiency. Sparse MoE models learn to dynamically route each input token to a specialized subset of model parameters (the “experts”) who have the skills required to process it. This decouples the model’s total capacity from the computational cost required to process each token.
The model is also natively multimodal, accepting text, images, audio, and video files within a 1 million token context window. It can generate text outputs of up to 192,000 tokens, making it capable of solving problems that require very long reasoning chains. In comparison, Gemini 2.5 Pro has an output capacity of 65,536 tokens.
Unfortunately, there is very little on both the model architecture and training techniques. From what we know, it seems that Google mostly changed the post-training regime to enable the model to generate more coherent chain-of-thought (CoT) sequences. At the same time, it has combined both RL and multi-sampling techniques that enable the model to not only think longer but also sample multiple answers, refine them and then combine them to generate the final answer.
Performance on complex benchmarks

Deep Think’s performance is demonstrated on benchmarks that measure creative and strategic problem-solving. On the USA Math Olympiad, the model reaches the 65th percentile of participants, a notable improvement over the 50th percentile achieved by Gemini 2.5 Pro.
It also achieves state-of-the-art performance on LiveCodeBench V6, a competitive coding benchmark, and Humanity’s Last Exam, which measures expertise across domains like science and math. This capability translates to practical applications requiring iterative development. An example shared by Google shows that Deep Think can design complex composite graphics with much more details than previous versions of Gemini. Deep Think can improve both the aesthetics and functionality of a website or excel at tough coding problems where problem formulation and time complexity are critical. (It also performs well on Simon Willison’s famous “pelican riding on a bicycle” test.)

How does this translate into real-world applications? It remains to be seen. I don’t have access to the model yet, but from the examples that other users have shared on X, it seems that Gemini Deep Think is impressively good at handling complex prompts in one shot. (Note that practically, you will usually want to solve a task over several iterations, so Deep Think might give you a good place to start with, and then you can make the small adjustments with smaller and less expensive models such as Gemini 2.5 Flash or Pro.)

Access and safety considerations
Google is rolling out Deep Think in phases. For the moment, it is very limited. Google AI Ultra subscribers ($250 per month) can access the model in the Gemini app for a fixed number of prompts per day. This version integrates with tools like Google Search and code execution.
Logan Kilpatrick, the product lead for Google AI Studio, suggested on X that the current limitations are due to the huge costs of running the model. This might mean that in the future, Gemini 2.5 Deep Think will become more widely available as Google figures out how to optimize its inference infrastructure and run it at scale.
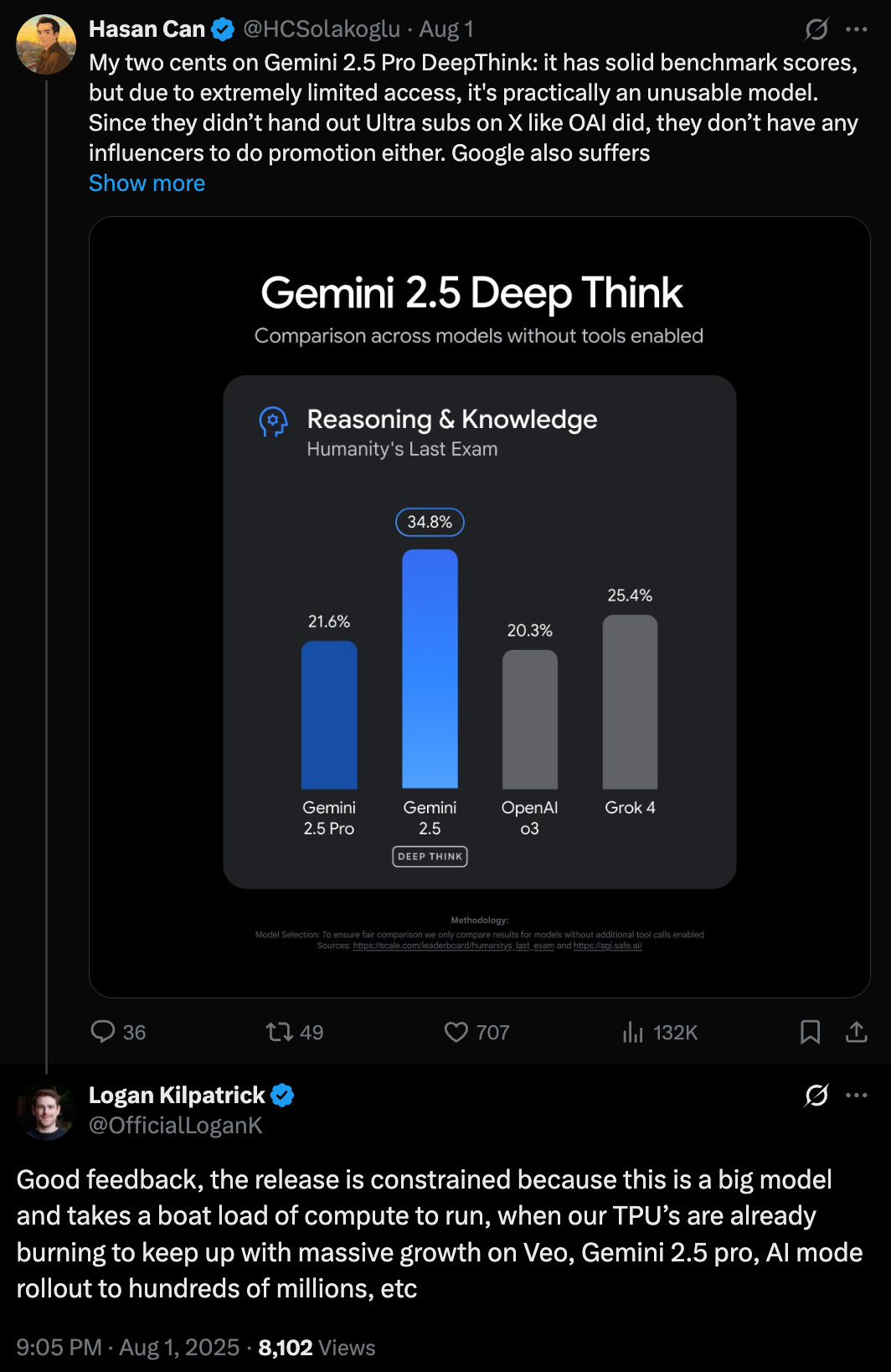
A small group of mathematicians and academics will receive access to the full IMO gold-medal version to enhance their research. In the coming weeks, Google also plans to release Deep Think through the Gemini API to a set of trusted testers. While tests show improved content safety and tone-objectivity compared to Gemini 2.5 Pro, the model has a higher tendency to refuse benign requests. Google states it is taking a deeper look at risks associated with this increased complexity through its frontier safety evaluations.
Tested it today, one of the best interactions with LLMs ever.