
Why I'm excited about Meta's new object segmentation model
With so much focus on LLMs, Meta's SAM 2 has not received the recognition it deserves.


Meta recently released SAM 2, the successor to its Segment Anything Model, released in 2023, and it is very impressive.
Not only is it a high-performance model for object segmentation on images and videos, SAM 2 is also a good tool for annotating data that can be used to train other models, including vision-language models (VLMs).
The original SAM was built based on an architecture that encodes an input image and a prompt (points, bounding boxes, etc.) and then finds the pixels in the image that correspond to the object(s) that the user has designated. While this approach proved very effective, it was not very accurate on videos, where objects can change across different frames, such as being deformed or occluded.
SAM 2 upgrades the original architecture with memory components that allow it to track objects across frames. In addition to seeing the encoding of each image, the model will also have access to the attention of previous frames, which will help better guide it in matching the user’s prompt to the right pixels.
SAM 2 can do a lot of things out of the box as it has been trained on a very large dataset of examples from 47 countries and different environments.
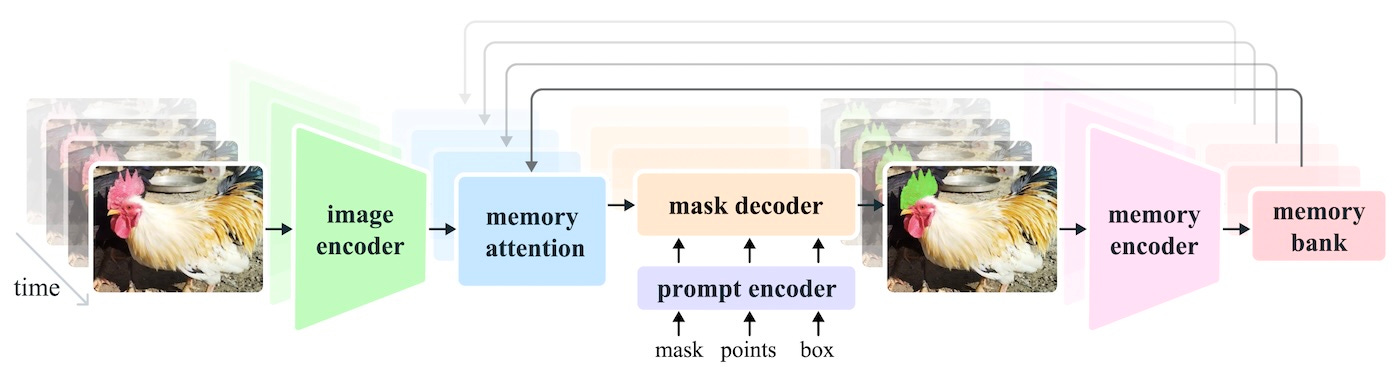
But what is really impressive about the model is how it can help train new models. Engineers and developers can use SAM 2 to overcome one of the main hurdles of creating specialized object segmentation models, which is to create training examples.
When used as a semi-automated annotation tool (where the model does the initial segmentation and a human makes corrections), it is many times faster than other similar models, including SAM.
This is especially useful for areas such as self-driving cars or industrial AI, which require very specialized models.
But another interesting direction can be the combination of SAM 2 with LLMs and VLMs. Multimodal models are showing impressive results in various applications, and they are mostly trained on raw pixels and text descriptions. It will be interesting to see if we add object segmentation data to the input modalities, what kind of new applications we can unlock.
Read more about SAM 2 on TechTalks.
Read the blog post on Meta’s AI blog.