
Why JEPA could be the key to more robust and efficient LLMs
A technique proven in computer vision is now being applied to language models, aiming for a deeper level of understanding and superior task performance.


Researchers from Atlassian, New York University, and Brown University have proposed a new way to train large language models (LLMs) by combining them with a powerful deep learning concept called the Joint Embedding Predictive Architecture (JEPA).
The technique, outlined in a new paper co-authored by Meta’s chief AI scientist Yann LeCun, modifies how LLMs are trained to improve their understanding of data. The initial results show that this approach can make models more efficient to train and more robust against overfitting.
Reconstruction vs. representation
Most modern AI models fall into two categories: reconstruction-based (or generative) and reconstruction-free. Generative models, as the name suggests, are trained to generate or reconstruct data. For example, an LLM learns by predicting the next word in a sequence, and an image diffusion model learns to reconstruct a clean image from a noisy one. This approach is very effective for creating detailed outputs like long-form text and high-resolution images. As the paper notes, the standard training objective for LLMs is “autoregressive token-space reconstruction.”
Reconstruction-free models like JEPA work differently. Instead of predicting every single detail (like every pixel in an image), they learn to predict abstract representations of data in a compressed, latent space. For example, a JEPA model can be trained to recognize that two different pictures of a cat are views of the same object, because it has learned a high-level representation of what “cat” means. These models are often more parameter-efficient because they don’t need to generate fine-grained outputs. This makes them ideal for building world models, where an AI system learns the underlying rules of an environment without needing to predict what every pixel will do next.
Bringing JEPA to language models
While JEPA has shown great promise in computer vision, applying it to language has been challenging because LLMs are primarily judged on their ability to generate text. However, many tasks that LLMs perform, such as reasoning and perception, are areas where JEPA-style learning is known to be superior. The researchers write, “It thus seems crucial to adapt JEPA solutions to LLMs in the hope to showcase the same benefits as witnessed in vision.”
The proposed method, LLM-JEPA, combines both training approaches. It preserves the standard next-token prediction objective to maintain the model’s generative power. At the same time, it adds a JEPA objective to improve the model’s ability to form abstract representations. This dual objective trains the model to understand the world on a deeper level without sacrificing its ability to generate text.
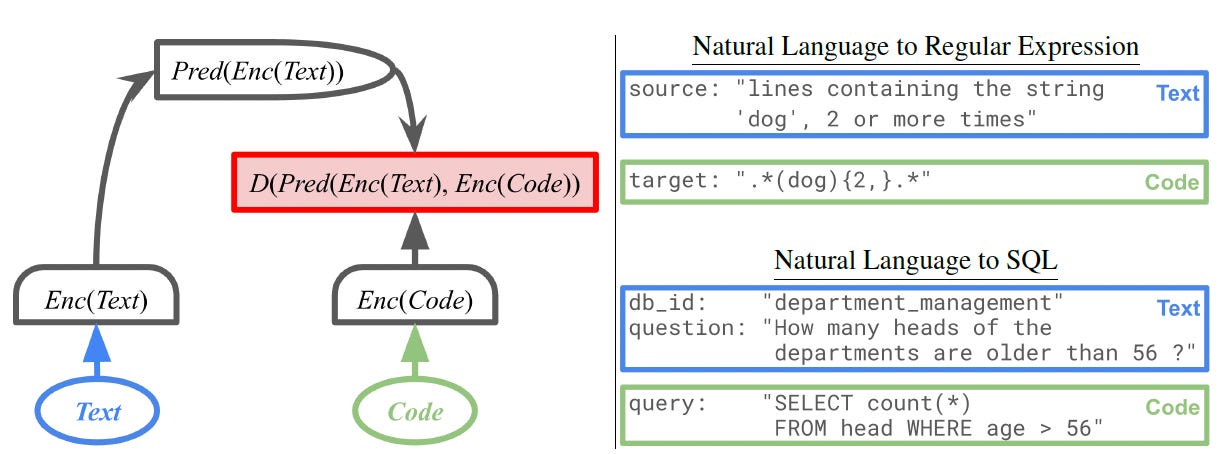
To train LLM-JEPA, the researchers needed datasets with “multiple views of the same underlying knowledge.” A perfect example is a programming task where one view is a natural language description of a problem (e.g., a GitHub issue) and the other view is the code that solves it. The model learns that the text and the code are different representations of the same core concept. This requires additional forward passes during training (one for the text and one for the code) which adds to the computational cost. However, this overhead does not affect the model’s speed at inference time. The authors suggest this is just a starting point, noting, “developing a mechanism akin to data-augmentation in vision would enable JEPA objectives to be used on any dataset.”
Promising early results
The researchers tested LLM-JEPA by fine-tuning and pretraining several models, including those from the Llama3, Gemma2, OpenELM, and Olmo families, on datasets like NL-RX, GSM8K, and Spider. The experiments showed that the LLM-JEPA training method consistently improved performance in both finetuning and pretraining scenarios. The authors state that their proposed method “maintains the generative capabilities of LLMs while improving their abstract prompt representation as empirically validated across datasets and models.”
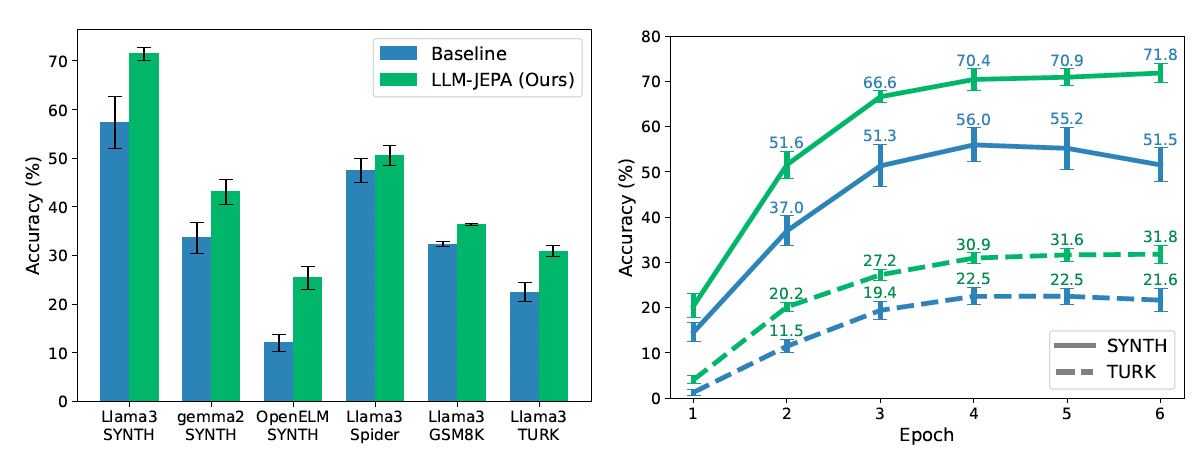
The primary drawback identified is “the 3-fold compute cost during training required to obtain the representations of the views,” which the team plans to address in future work. Despite this limitation, the paper presents a compelling new direction for LLM development. The researchers conclude, “we believe that our proposed solution… and empirical study will serve as a first step towards more JEPA-centric LLM pretraining and finetuning.”
JEPA and GEPA are useful. We came up with something leaner called MeP (mise en place). It's a cooking term. It's when a lesser agent places the tools and preps the ingredients for the master chef.
You don't need a chef to chop celery.
If LLMs through JEPA start forming abstract meanings, it won’t be human intelligence, but it may be the first step toward systems that learn meaning rather than only form.